
Ein Tischkicker dient als Anschauungsobjekt, um die Kapazitäten von SAP Data Intelligence, SAP Warehouse Cloud und SAP Analytics Cloud zu demonstrieren. Im folgenden Artikel wird das Setup erläutert.
CAMELOT Village hieß das globale Event zur Feier des 25-jährigen Firmenjubiläums. Mehr als 600 Kolleginnen und Kollegen nahmen in Mayrhofen an verschiedenen Aktivitäten und Workshops teil.
Eine der Hauptattraktionen war der Marktplatz, auf dem die Geschäftsbereiche des Unternehmens Exponate zu aktuellen Themen rund um Kundenprojekte und interne Projekte präsentierten.
Zu diesem Anlass hatten einige Datenexperten einen Tischkicker gebaut, mit dessen Hilfe die Kapazitäten unterschiedlicher SAP-Technologien wie SAP Data Intelligence, SAP Warehouse Cloud und SAP Analytics Cloud demonstriert werden sollten. Zweck des Setups war es, Spielstatistiken in Echtzeit zu zählen und sie entsprechend auf einem SAC-Dashboard anzuzeigen.
Der Tischkicker befand sich dabei innerhalb eines Rahmens, an dem von oben eine Kamera angebracht war. Die Kamerahöhe wurde zunächst manuell so justiert, dass das gesamte Spielfeld abgedeckt war. Dann wurde sie fest an einem Holzrahmen montiert, sodass sie kontinuierlich Echtzeitdaten zur Weiterverarbeitung generieren konnte. Dabei wurde darauf geachtet, dass die Kamera während des Spiels ungestört aufzeichnen konnte.

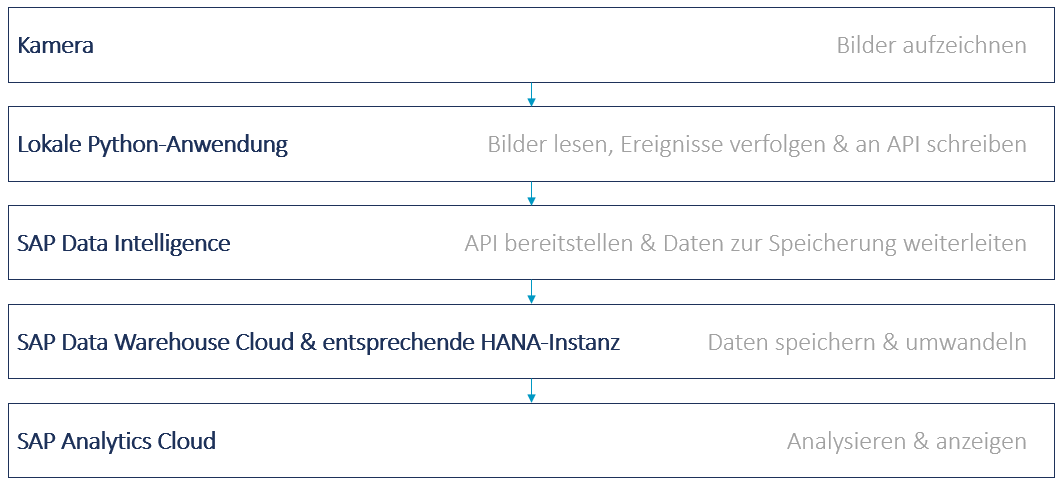
Der Artikel liefert einen Überblick über die Datenfluss-Architektur und die zugrundeliegende Python-Anwendung.
Überblick über die Datenfluss-Architektur
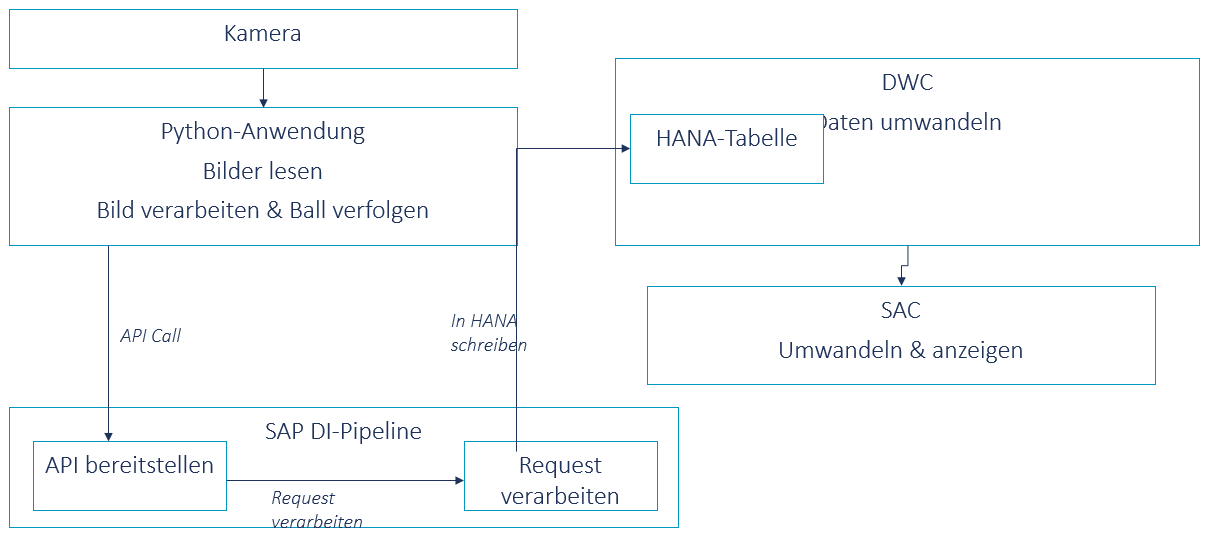
Abbildung 2 liefert einen Überblick über die allgemeine Datenfluss-Architektur. Auf der lokalen Seite wickelt eine Python-Anwendung die Datenverarbeitung ab. Sie erfasst die Daten der über dem Kickertisch montierten Kamera und verarbeitet diese, sodass verschiedene Ereignisse auf dem Spielfeld extrahiert werden können.
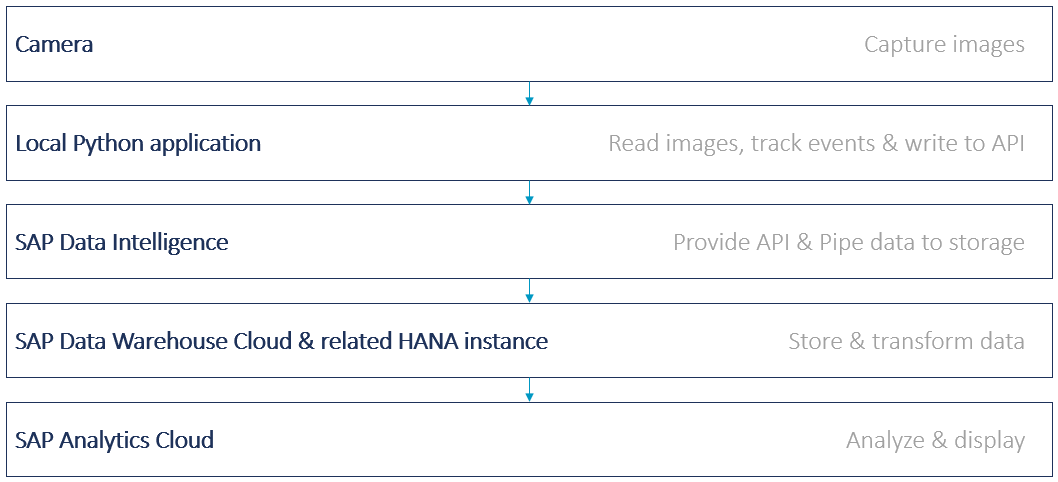
Diese Ereignisse werden dann an eine REST API übertragen, die von SAP Data Intelligence bereitgestellt wird. Die REST-API ist in SAP Data Intelligence als Pipeline implementiert, die die Daten bei jeder Anfrage verarbeitet. Das bedeutet, dass sie Informationen in einer HANA-Datenbank speichert und abruft, die in diesem Fall die zugrunde liegende HANA-Datenbank der SAP Data Warehouse Cloud war. SAP Data Warehouse Cloud extrahiert die Daten dann als Ansichten und übermittelt sie an SAP Analytics Cloud. Hier werden die Daten schließlich analysiert, abgerufen und auf einem Dashboard angezeigt.
Datenaufzeichnung
Im Folgenden sind die verschiedenen Kameramodelle aufgeführt, die für dieses Setup getestet wurden, sowie das Kameramodell, das schließlich in den Projektaufbau implementiert wurde.
- Modell 1 mit hoher Bildrate wurde nicht ausgewählt, weil die API-Kommunikation nicht einwandfrei funktionierte.
- Modell 2 mit 60 FPS eignete sich nicht, da die Bildfarben unnatürlich waren.
- Modell 3 mit 30 FPS wurde schließlich eingesetzt, ist aber nicht ideal geeignet, da die Bildrate zu niedrig ist für Highspeed-Aufnahmen.
Wenn Sie eine Kamera für Ihr Setup testen wollen, raten wir dazu, Kameras mit mehr als 30 FPS zu wählen – unter Umständen müssen auch mehrere Kameras ausprobiert werden.
Lokale Python-Anwendung
Die Ballverfolgung erfolgte mit einem lokalen Python-Modul auf Basis von OpenCV, einer häufig genutzten Open-Source-Bibliothek für Computer Vision. Neben der Bildverarbeitung unterstützt OpenCV auch die Verarbeitung von Videos, sowohl aufgezeichnet als auch live. Mit OpenCV kann die automatische Öffnung von Aufnahmegeräten wie Webcams programmiert werden, und jedes aufgezeichnete Bild kann anschließend in unsere Ballverfolgungsfunktion eingespeist werden. Damit ist OpenCV für unseren Anwendungsfall perfekt geeignet.
Bildvorverarbeitung
Die Anzahl der Bilder, die OpenCV ausgibt, hängt von der Bildrate der Kamera ab. Im vorliegenden Fall beträgt die Bildrate 30 Bilder pro Sekunde (Frames per Second, FPS). Jedes Bild wird von OpenCV als Image Array ausgegeben. Bevor wir dieses Bild in die Ballverfolgungsfunktion einspeisen, durchläuft es folgende Verarbeitungsschritte:
- Skalierung,
- Zuschnitt des Bildes, sodass nur das tatsächliche Feld übrigbleibt,
- Konvertierung in den HSV-Farbraum, da dieser am besten für die Objekterkennung geeignet ist,
- Erstellung einer Bildmaske zur Identifizierung der Pixel, die innerhalb des im Kalibrierungsschritt für den Ball festgelegten Farbbereichs liegen,
- Anwendung von Dilatation und morphologischer Extraktion auf die verbleibenden Pixel,
- Erkennung der Konturen im dilatierten und gemorphten Bild.
Nachdem diese Verarbeitungsschritte nacheinander durchgeführt wurden, werden die im Bild erkannten Konturen an die eigentliche Ballverfolgungsfunktion weitergegeben.
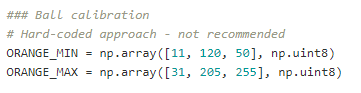
Kalibrierung für die Ballerkennung
Der Ball wird verfolgt, indem die Pixel im Bild gesucht werden, die 1) in einem vergleichbaren Farbbereich liegen wie die Ballfarbe und 2) zusammen einen Kreis bilden, der der Form des Balls ähnelt, der für das Spiel verwendet wird. Wir müssen daher entsprechende Grenzwerte für den Radius eines erkannten Kreises festlegen, damit dieser Kreis als der tatsächliche Ball erkannt wird. Durch Festlegung dieser Grenzwerte können wir auch Rauschen, z. B. aufgrund von Lichtreflexionen, herausfiltern.
Um den Farbbereich des Balles festzulegen, führen wir jedes Mal, wenn das Verfolgungstool neu gestartet wird, einen Kalibrierungsschritt durch. Damit die Kalibrierung gelingt, muss der Ball auf dem Mittelpunkt des Felds liegen, wenn das Modul gestartet wird, da das mittlere Pixel des Bildes als Ankerpunkt für die Definition des Farbbereichs verwendet wird. Wir erweitern den Farbbereich rund um das mittlere Pixel um einen Toleranzbereich nach oben und unten, da die HSV-Werte aufgrund von Lichtreflexionen und Schatten leicht variieren können.
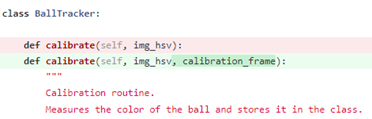
Ballverfolgung
Die Ballverfolgungsfunktion basiert auf den Konturen des verarbeiteten Bildes. Konturen sind sehr nützlich für die Formenanalyse und die Objekterkennung. In unserem Fall bieten sie uns die Möglichkeit, Formen zu erkennen, die dem Ball ähneln. Für jede Kontur identifizieren wir den Umfang und den Radius des geschlossenen Kreises, und nur wenn beide Werte innerhalb unserer definierten Grenzen liegen, wird die Kontur als geeigneter Ballkandidat angesehen. Die Grenzwerte wurden nach umfassenden manuellen Tests hartkodiert. Dieser Ansatz erwies sich als sehr erfolgreich für die Verfolgung des Balls. Für ein ansprechenderes Benutzererlebnis zeichnen wir einen Kreis rund um jeden erkannten Ball und fügen Informationen über seine Koordinaten, seine Fläche und seinen Radius hinzu, sodass die Spieler sehen können, wie der Ball während des Spiels verfolgt wird.
Heuristiken für die Torerkennung
Nachdem wir etwas experimentiert hatten, wie man Tore zuverlässig tracken kann, landeten wir bei einer einfachen, aber gleichzeitig pragmatischen Heuristik: Zunächst bestimmten wir die y-Koordinaten der linken und rechten Torpfosten, um den Torbereich in vertikaler Richtung abzugrenzen. Dann bestimmten wir die x-Koordinaten beider Torlinien. Wir mussten jedoch feststellen, dass die Nutzung der Torlinienkoordinaten als Grenzwerte dazu führte, dass uns zu viele Tore entgingen. Dies hat direkt mit der allgemeinen Problematik zu tun, mit der wir im Prozess der Torerkennung konfrontiert waren. Wie bereits zuvor erwähnt, nimmt die von uns genutzte Kamera nur 30 Bilder pro Sekunde auf, was sich in einigen Fällen als nicht ausreichend erwies, um Tore zuverlässig zu tracken. Vor allem Torschüsse mit hoher Geschwindigkeit konnten nicht überprüft werden. In diesen Fällen war die Ballgeschwindigkeit so hoch, dass die Torlinie bereits erneut passiert wurde, bevor das nächste Bild aufgenommen wurde, sodass es kein Bild vom Ball hinter der Torlinie gab. Um dieses Problem zu lösen, beschlossen wir, nicht die Torlinien als x-Grenzwerte zu wählen, sondern stattdessen die Linie, die den Torbereich abgrenzt. Dies reduzierte den negativen Einfluss der Bildrate auf die Torerkennung erheblich, jedoch nicht vollständig.
Wir mussten auch sicherstellen, dass ein und dasselbe Tor nicht mehrfach gezählt wird. Wenn sich ein Ball in einem Bild innerhalb unserer definierten x- und y-Grenzen für die Torverfolgung befand, wurde die Bool-Variable goal_black bzw. goal_white auf „true“ gesetzt. Wenn ein Tor geschossen wird, gibt es jedoch in der Regel mehrere aufgezeichnete Bilder dieses Tors, wir wollen das Tor aber nur einmal zählen. Um eine Mehrfachzählung von Toren zu verhindern, entwickelten wir die folgende Heuristik: Die Anzahl der Tore wird nur erhöht, wenn entweder die Variable goal_white oder goal_black auf „true“ gesetzt wird UND auf 50 aufeinander folgenden Bildern kein Ball erkannt wird. So wird sichergestellt, dass nur für das letzte Bild, das den Ball hinter der Torlinie erfasst, ein Tor gezählt wird.

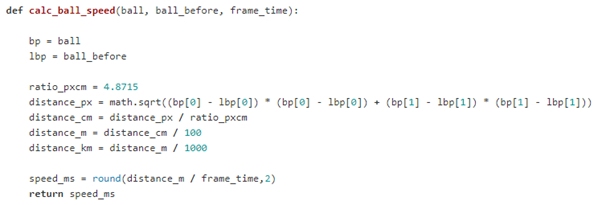
Einrichtung der Geschwindigkeitsmessung
Die Ballgeschwindigkeit wurde berechnet, indem die vom Ball zwischen zwei Bildern zurückgelegte Distanz durch die Zeit geteilt wurde, die zwischen zwei Bildern lag. Da die Ballkoordinaten in Pixeln angegeben werden, bestand eine Aufgabe darin, das richtige Verhältnis zwischen Pixeln und Zentimetern zu finden, um die Distanz in Zentimeter umrechnen zu können. Zu diesem Zweck nutzten wir die Distanz zwischen den Torbereichen für die Kalibrierung: Wir bestimmten zunächst die tatsächliche Distanz zwischen den beiden Torbereichen in Zentimetern, dann dieselbe Distanz auf dem Bild in Pixeln (mit OpenCV) und teilten anschließend die Zentimeter durch die Pixel. So ergab sich ein Verhältnis von Pixeln zu Zentimetern von 4,8715, was bedeutet, dass ein Pixel 4,8715 Zentimeter des tatsächlichen Spielfelds darstellt.
Initialisierung und Beendigung von Spielen
Die automatische Initialisierung des Moduls stellte die erste Spielinstanz dar. Jedem Spiel wird eine Game-ID zugewiesen, damit eine detailliertere Analyse durch SAP Analytics Cloud möglich ist. Wir beschlossen, die Dauer eines Spiels auf 5 Minuten zu begrenzen, und verfolgten die Spieldauer mit einem Bildzähler. Da die Kamera 30 Bilder pro Sekunde schießt, ergeben sich über einen Zeitraum von 5 Minuten 9.000 Bilder. Diesen Wert nutzten wir als Grenzwert für das Ende eines Spiels. Sobald der Grenzwert erreicht ist, erscheint auf dem Bildschirm eine Mitteilung für die Spieler, dass das Spiel beendet ist. Um das nächste Spiel zu starten, muss eine beliebige Taste auf der Tastatur gedrückt werden. Im Backend initalisiert der Tastendruck ein neues Spiel, indem eine neue Game-ID vergeben wird und Score und Timer zurückgesetzt werden.
Felderkennung
Die Feld-/Spielgrenzen und der Mittelpunkt wurden manuell mittels OpenCV-Callback-Funktionen festgelegt, die beim Anklicken ausgewählter Punkte auf dem Bild die x-/y-Koordinaten ausgaben.

SAP Data Intelligence
Die persistente Speicherung der Daten erfolgt durch SAP Data Intelligence über eine Pipeline. Die Pipeline ist permanent aktiv und führt die Persistenzlogik aus, sobald sie einen API-Call abruft. Der Operator „OpenAPI Servelow“ gibt die API an eine persistente URL-Adresse weiter, d. h. die URL ändert sich nicht, wenn die Pipeline neu gestartet wird. So kann die Pipeline auf einfache Weise deaktiviert werden, wenn die API nicht gebraucht wird.
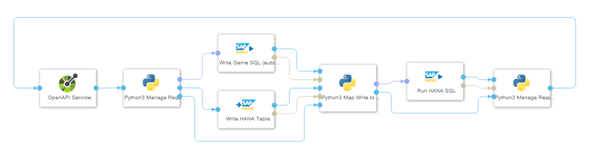
Die Pipeline selbst umfasst drei benutzerdefinierte Python-Operatoren, die den Datenfluss verwalten. Auf Basis der operation_id in den eingehenden Nachrichten entscheiden die Python-Operatoren, wie die Daten behandelt werden. Die Operatoren haben folgende Aufgaben:
- Der erste und zweite Python-Operator ist verantwortlich für die Weiterleitung der Daten an die HANA-Operatoren, falls notwendig. Wenn ein API Call einen HANA-Operator nicht benötigt, gibt der Python-Operator die Nachricht einfach an den nächsten Python-Operator weiter.
- Der zweite und dritte Python-Operator bearbeiten die Antwort des HANA-Operators und eventuelle Fehler.
- Der dritte Python-Operator nimmt alle Nachrichten entgegen und ist verantwortlich für den Versand der Nachricht, die der Operator „OpenAPI Servelow“ als Antwort auf den HTTP-Request ausgibt.
Die HANA-Operatoren lesen oder schreiben die Informationen, die die Python-Operatoren ihnen bereitstellen oder von ihnen abrufen. Siehe Abbildung 3 für die INSERT-Statements der HANA-Tabellen, in denen die Informationen persistent gespeichert werden. Im Folgenden beschreiben wir für jedes Datenelement, worin die entsprechende Aufgabe der HANA-Operatoren besteht:
- Der API-Endpunkt GAME erstellt ein neues Spiel und gibt die entsprechenden Informationen einschließlich der GAME_ID als Antwort aus. Es wird ein Array mit den Spieldaten erwartet, die zu diesem Zeitpunkt nur aus dem Start-Zeitstempel des Spiels bestehen. Da der Operator „Write HANA table“ Probleme hat, die Daten einzufügen, wenn es keine Schlüsselspalte gibt, nutzen wir den Operator „Run HANA SQL“ zum Einfügen der Daten in die HANA-Tabelle. Ungünstigerweise gibt der Operator „Write HANA table“ keine Spalten aus, die nicht in den Operator eingespeist werden, daher gibt der Operator „Run HANA SQL“ None aus, wenn eine INSERT-Abfrage erfolgt. Aus diesem Grund müssen wir das Spiel mit einer GAME_ID von MAX(GAME_ID) einlesen, um die GAME_ID in der Antwort ausgeben zu können. Mit diesem Setup können wir es in späteren Calls der APIs GOAL und SPEED als Referenz verwenden.
- Der API-Endpunkt GOAL erstellt mit den eingehenden Informationen einen neuen Spieleintrag. Dabei wird ein Array mit den Spieldaten erwartet, zu denen die ID des Spiels gehört, auf das sich der Vorgang bezieht, die ID des Teams, das das Tor geschossen hat, sowie die Spielminute und ein Zeitstempel, die sich auf den Zeitpunkt des erzielten Tors beziehen.
- Der API-Endpunkt SPEED speichert die eingehenden Geschwindigkeitsdaten persistent und kann sowohl Einzeleinträge als auch Batch-Daten verarbeiten. Es wird dafür entweder ein Array mit einem Geschwindigkeitseintrag oder eine Reihe von Arrays mit Geschwindigkeitseinträgen erwartet. Ein Array enthält Informationen über die ID des Spiels, auf das es sich bezieht, die Schussgeschwindigkeit und die Sekunde, in der der Geschwindigkeitswert aufgezeichnet wurde (einschließlich Millisekunden im Nachkommabereich der Gleitkommazahl).
Spiele:

Tore:

Informationen zur Ballgeschwindigkeit:

SAP Data Warehouse Cloud
In SAP Data Warehouse Cloud hat das Projekt seinen eigenen Bereich. In diesem Bereich wird ein Datenbankbenutzer mit Lese- und Schreibrechten angelegt. Mit den Anmeldedaten dieses Benutzers kann SAP Data Intelligence eine direkte Verknüpfung zur zugrundeliegenden Datenbank von SAP Data Warehouse Cloud erstellen und die eingehenden Daten dort persistent speichern.
Die Daten der verschiedenen Tabellen werden in verschiedenen Ansichten aggregiert, um SAP Analytics Cloud die relevanten Daten zur Verfügung zu stellen. Einerseits gibt es jeweils eine Ansicht für die Tore und die Geschwindigkeitsinformationen des aktuellen Spiels, d. h. des Spiels mit einer GAME_ID von MAX(GAME_ID). Andererseits gibt es eine Ansicht für die Tore, die im vorherigen Spiel erzielt wurden, d. h. des Spiels mit einer GAME_ID von MAX(GAME_ID)-1.
SAP Analytics Cloud
SAC wird hauptsächlich für die Frontend-Seite der Erstellung eines statistischen Dashboards sowie dessen Verknüpfung mit DWC und SAP Data Intelligence für die Umwandlung und Anzeige der Daten verwendet. Das Dashboard zeigt sowohl die statistischen Daten für das aktuelle Spiel als auch für alle bisher gespielten Spiele an. Die Gesamtzahl, der von jedem Team erzielten Tore wurde mittels Live-Verbindung in Echtzeit berechnet, und die Tore pro Minute wurden zudem mit Hilfe von Balkenanzeigen wie in der Abbildung unten dargestellt.
Fazit
Insgesamt verdeutlicht das Projekt die Kombination von Tools für interne und externe Kundenprojekte auf hochtechnische Weise. Dabei haben wir uns auf die Verbindung zwischen unterschiedlichen Systemen konzentriert, die zusammen ein vollständig funktionstüchtiges Produkt ergeben, von Backend-Technologien wie SAP Data Intelligence bis zur Dashboard-Erstellung im Frontend mit Hilfe von SAP Analytics Cloud.

By loading the video, you agree to YouTube’s privacy policy.
Learn more
Kleiner Bonus: Das Spielen hat auch Spaß gemacht!
