
Im Zeitalter der digitalen Transformation sollten Unternehmen Machine-Learning-Methoden zur Optimierung ihrer Prozesse einsetzen. Es wurde viel darüber berichtet, wie Computer aus früheren Beobachtungen lernen und neue Informationen ableiten können. Doch wie funktioniert die Verwandlung von Daten in Mehrwerte für das Unternehmen? Dieser Artikel beschreibt, wie wir Data Science zur Gewinnung von Erkenntnissen in Ihrer Organisation einsetzen können, um die Herausforderungen realer Daten zu meistern und so Werte zu schaffen und Prozesse zu verbessern.
Machine Learning (ML) kann große Mehrwerte für Ihr Unternehmen schaffen. Wir alle haben diesen Satz schon oft gehört. Im Zeitalter der digitalen Transformation sowie des KI-basierten Arbeitens liegen die Vorteile der Implementierung von ML in Ihrer Organisation auf der Hand. Doch wie können wir Data Science nutzen, um Einblicke in unsere Daten zu gewinnen? Und, noch wichtiger, wie können wir das vorhandene Wissen erfahrener Geschäftsexperten nutzen, um ML bei der Verwandlung von Daten in Werte zu unterstützen?
Daten sind wichtig, aber das Geschäft ist entscheidend
Mit ML können wir historische Informationen nutzen, um Schlüsse für die Zukunft zu ziehen und dabei die Lösungen eines Problems zu verallgemeinern. Dabei sollte man jedoch bedenken, dass ML kein Wundermittel ist und dass eine gute Datenqualität für diesen Prozess der Schlussfolgerung und Verallgemeinerung unerlässlich ist. Wenn unsere Daten nicht die Realität des Geschäfts abbilden, können unsere Modelle nicht lernen, wie sie eine Lösung dafür verallgemeinern sollen. Es wird viel diskutiert über Datenqualität und die Frage, was gute Daten sind, doch sprengt dies den Rahmen dieses Beitrags und kann in einem separaten Blogpost veröffentlicht werden. Worum es mir hier geht, ist, dass ML Ihr Geschäft unterstützen soll, das alle Ihre Prozesse schon koordinierte, als KI noch lange kein Thema war. Das bedeutet, dass niemand die mit ML und KI lösbaren Herausforderungen Ihres Geschäfts besser kennt als Ihre Geschäftsexperten. Ihr Wissen und ihre Erfahrung sind entscheidend, um Erkenntnisse aus Ihren Daten gewinnen zu können.
Bestimmung von Faktoren als Brücke zwischen Business und ML
Doch wie können wir das Wissen unserer fähigsten Experten in eine Sprache überführen, die Maschinen verstehen können? Hierbei spielt die Bestimmung von Faktoren eine wichtige Rolle. Beispielsweise könnte die Reduzierung von Verzögerungen bei einer Produktionsplanung ein Ziel sein. Hierfür müssen wir Standardzeiten für einen Prozess festlegen, unter Berücksichtigung von Faktoren, die gewöhnlich Verzögerungen in der Produktion verursachen. Wir beschließen, ML zur Bestimmung der häufigsten Ursachen für Verzögerungen einzusetzen. In ständigem Austausch mit dem für die Festlegung der Standardzeit eines Prozesses zuständigen Planer stellten wir fest, dass neue Maschinen (weniger als 3 Monate alt) für jeden Prozess mehr Zeit benötigen können, da die Mitarbeiter noch nicht gut mit der Einrichtung der Maschine vertraut sind. Auf der anderen Seite können auch alte Maschinen (älter als 5 Jahre) langsamer als der Durchschnitt sein, da neuere Modelle neue Technologien nutzen. Ausgehend von diesen Informationen können wir durch die Bestimmung von Faktoren das Wissen der Experten in unser ML-Modell einfließen lassen. Da wir die Verzögerungen vorhersehen wollen, müssen wir sie anhand der Differenz zwischen Standardzeiten und bestätigten Zeiten berechnen. Die Bestimmung von Faktoren sieht hier etwa so aus:  Da wir die häufigsten Ursachen für Verzögerungen herausfinden wollen, müssen wir auch weitere mögliche Gründe für die Verzögerung eines Prozesses berücksichtigen. Statistisch ausgedrückt, sind diese die Hypothese, die wir mithilfe eines ML-Modells bestätigen wollen. Bei weiteren Gesprächen mit dem für die Produktion verantwortlichen Planer haben wir entschieden, dass die häufigsten Gründe folgende sind:
Da wir die häufigsten Ursachen für Verzögerungen herausfinden wollen, müssen wir auch weitere mögliche Gründe für die Verzögerung eines Prozesses berücksichtigen. Statistisch ausgedrückt, sind diese die Hypothese, die wir mithilfe eines ML-Modells bestätigen wollen. Bei weiteren Gesprächen mit dem für die Produktion verantwortlichen Planer haben wir entschieden, dass die häufigsten Gründe folgende sind:
- Maschinenalter (zu neu oder zu alt): Wie bereits erwähnt, sind neue Maschinen schwieriger einzurichten und alte Maschinen besitzen veraltete Technik.
- Saisonbedingter Anstieg der Nachfrage: Die Produktionsplanung versucht stets, die Nachfrage so gut wie möglich zu decken. Eine erhöhte Nachfrage bedeutet auch längere Durchlaufzeiten, was Verzögerungen verursacht.
- An einem bestimmten Tag reduzierte Mitarbeiterzahl: Genau wie der Anstieg der Nachfrage verursachen fehlende Mitarbeiter eine Überlastung der an einem bestimmten Tag tätigen Mitarbeiter und somit eine Verzögerung der Produktion.
- Ausfall einer Maschine: Unerwartete Ausfälle von Maschinen verursachen eine Überlastung der funktionierenden Maschinen und Verzögerungen bei der Produktion der entsprechenden Materialien.
- Mitarbeiterqualifikationen: Die Dauer der Unternehmenszugehörigkeit eines Mitarbeiters ist ein guter Indikator für seine/ihre Erfahrung. Je erfahrener ein Mitarbeiter ist, desto schneller arbeitet er/sie. Dies ist ein guter Indikator für Verzögerungen, allerdings steht die Information gewöhnlich (aus Datenschutzgründen) nicht zur Verfügung und wird daher in diesem Artikel nicht berücksichtigt.
Überträgt man alle diese Ursachen in eine ML-Notation, erhalten wir die folgende Faktorenmatrix:  Mit unserer Faktorenmatrix können wir die häufigsten Ursachen von Verzögerungen analysieren. Bedeutung von Faktoren: der erste Schritt einer Kausalitätsanalyse Bei auf Baumdarstellungen basierenden ML-Algorithmen wie Random Forests oder Entscheidungsbäumen ist die Bedeutung von Faktoren eine Kennzahl, die angibt, wie relevant ein bestimmtes Merkmal für Ihr Modell ist. Mathematisch ausgedrückt, wird damit berechnet, wie viel besser Ihre Prognosen mit jedem neuen Knoten in Ihrem Entscheidungsbaum werden, mit einer Gewichtung anhand der Wahrscheinlichkeit, diesen Knoten zu erreichen. Je höher der Wert, desto wichtiger ist Ihr Faktor. Diese Kennzahl kann für unsere Kausalitätsanalyse sehr wertvoll sein. Wir wollen die häufigsten Ursachen für unsere Produktionsverzögerungen ermitteln. Wir haben bereits gemeinsam mit unserem Geschäftsexperten unsere Hypothese definiert und diese in unserer Faktorenmatrix umgesetzt. Nun können wir also diese Information zur Vorhersage der Verzögerung verwenden. Dabei ist zu bedenken, dass unser letztliches Ziel darin besteht, bessere Standardzeiten festzulegen, um diese Verzögerungen zu vermeiden. Durch deren Vorhersage können wir deren Ursachen bestimmen und mithilfe dieser Erkenntnis die neuen Standardzeiten festlegen. Schauen wir uns die mögliche Bedeutung von Faktoren an, die bei Anwendung eines Random-Forest-Modells auf unseren Datensatz generiert wird:
Mit unserer Faktorenmatrix können wir die häufigsten Ursachen von Verzögerungen analysieren. Bedeutung von Faktoren: der erste Schritt einer Kausalitätsanalyse Bei auf Baumdarstellungen basierenden ML-Algorithmen wie Random Forests oder Entscheidungsbäumen ist die Bedeutung von Faktoren eine Kennzahl, die angibt, wie relevant ein bestimmtes Merkmal für Ihr Modell ist. Mathematisch ausgedrückt, wird damit berechnet, wie viel besser Ihre Prognosen mit jedem neuen Knoten in Ihrem Entscheidungsbaum werden, mit einer Gewichtung anhand der Wahrscheinlichkeit, diesen Knoten zu erreichen. Je höher der Wert, desto wichtiger ist Ihr Faktor. Diese Kennzahl kann für unsere Kausalitätsanalyse sehr wertvoll sein. Wir wollen die häufigsten Ursachen für unsere Produktionsverzögerungen ermitteln. Wir haben bereits gemeinsam mit unserem Geschäftsexperten unsere Hypothese definiert und diese in unserer Faktorenmatrix umgesetzt. Nun können wir also diese Information zur Vorhersage der Verzögerung verwenden. Dabei ist zu bedenken, dass unser letztliches Ziel darin besteht, bessere Standardzeiten festzulegen, um diese Verzögerungen zu vermeiden. Durch deren Vorhersage können wir deren Ursachen bestimmen und mithilfe dieser Erkenntnis die neuen Standardzeiten festlegen. Schauen wir uns die mögliche Bedeutung von Faktoren an, die bei Anwendung eines Random-Forest-Modells auf unseren Datensatz generiert wird: 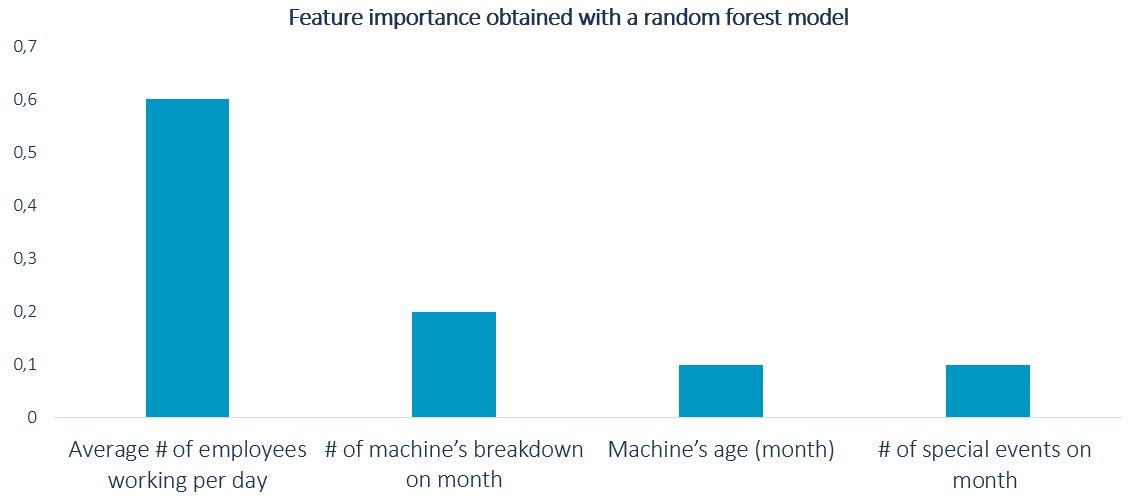 Aus der Grafik erkennen wir, dass die durchschnittliche Anzahl der pro Tag tätigen Mitarbeiter in einem Monat der wichtigste Einflusswert für die Verzögerung ist. Das bedeutet, dass die Standardproduktionszeiten vor allem in Hinblick auf die Verfügbarkeit der Mitarbeiter im jeweiligen Monat abgestimmt werden sollten. Außerdem sehen wir, dass die Anzahl der Maschinenausfälle in dem Monat einen wichtigen Faktor darstellt. Dies deutet darauf hin, dass eine außerplanmäßige Wartung für die Produktion sehr teuer werden kann. Eine Möglichkeit, diese Kosten zu senken, wäre die Einführung eines Projekts zur vorausschauenden Wartung, ein weiterer sehr häufiger Anwendungsfall für ML, der uns bei der Optimierung unserer Geschäftsprozesse unterstützen kann. Eine schnelle Investitionsrentabilität (ROI) wird möglich, wenn Machine Learning mit seinen Stärken und Grenzen verstanden wird Wie wir gesehen haben, ist ML ein leistungsstarkes, aber auch ein komplexes Werkzeug. Nur wenn man seine Stärken und Grenzen versteht, kann es zum Erreichen eines schnellen ROI beitragen. Um Daten in Wert zu verwandeln, müssen wir uns bewusst machen, dass KI/Data Science/Deep Learning und all die anderen aktuellen Trends lediglich Werkzeuge sind, die uns auf unserem Weg unterstützen können. Das Geschäft ist der Hauptfaktor für unsere Arbeit und sollte es auch bleiben. Die korrekte Umsetzung geschäftlicher Anforderungen in Daten (oder Faktoren) für unsere Modelle dient dazu, die Grundursachen für die von uns analysierten Ereignisse zu finden. Mathematische Ansätze wie die Faktorenbedeutung der Koeffizienten einer Regression können uns bei der Quantifizierung unserer Kausalanalyse unterstützen und die korrekte Interpretation der Ergebnisse ermöglicht uns die Optimierung unseres Geschäfts und die Schaffung von Wert mit ML.
Aus der Grafik erkennen wir, dass die durchschnittliche Anzahl der pro Tag tätigen Mitarbeiter in einem Monat der wichtigste Einflusswert für die Verzögerung ist. Das bedeutet, dass die Standardproduktionszeiten vor allem in Hinblick auf die Verfügbarkeit der Mitarbeiter im jeweiligen Monat abgestimmt werden sollten. Außerdem sehen wir, dass die Anzahl der Maschinenausfälle in dem Monat einen wichtigen Faktor darstellt. Dies deutet darauf hin, dass eine außerplanmäßige Wartung für die Produktion sehr teuer werden kann. Eine Möglichkeit, diese Kosten zu senken, wäre die Einführung eines Projekts zur vorausschauenden Wartung, ein weiterer sehr häufiger Anwendungsfall für ML, der uns bei der Optimierung unserer Geschäftsprozesse unterstützen kann. Eine schnelle Investitionsrentabilität (ROI) wird möglich, wenn Machine Learning mit seinen Stärken und Grenzen verstanden wird Wie wir gesehen haben, ist ML ein leistungsstarkes, aber auch ein komplexes Werkzeug. Nur wenn man seine Stärken und Grenzen versteht, kann es zum Erreichen eines schnellen ROI beitragen. Um Daten in Wert zu verwandeln, müssen wir uns bewusst machen, dass KI/Data Science/Deep Learning und all die anderen aktuellen Trends lediglich Werkzeuge sind, die uns auf unserem Weg unterstützen können. Das Geschäft ist der Hauptfaktor für unsere Arbeit und sollte es auch bleiben. Die korrekte Umsetzung geschäftlicher Anforderungen in Daten (oder Faktoren) für unsere Modelle dient dazu, die Grundursachen für die von uns analysierten Ereignisse zu finden. Mathematische Ansätze wie die Faktorenbedeutung der Koeffizienten einer Regression können uns bei der Quantifizierung unserer Kausalanalyse unterstützen und die korrekte Interpretation der Ergebnisse ermöglicht uns die Optimierung unseres Geschäfts und die Schaffung von Wert mit ML.
Wir danken Maíra Ladeira Tanke und Frank Kienle für deren Beitrag zu diesem Artikel.
