
Die Menge und Komplexität von Daten wachsen in Lichtgeschwindigkeit. Diese Daten liegen häufig in unstrukturierter Form vor, z. B. als Dokumente, Grafiken oder einfacher Text. Viele Unternehmen möchten von den verfügbaren Daten profitieren, aber die Klassifizierung komplexer Daten mit Metadaten allein reicht möglicherweise nicht mehr aus. Vektordatenbanken könnten eine Lösung für diese Herausforderung sein.
Trotz der enormen Entwicklung von Datenbanktechnologien, die Terabytes von Daten mit geringen Latenzzeiten verarbeiten können, haben Vektordatenbanken in letzter Zeit hohe Wellen geschlagen. In diesem Jahr erhielten drei Startups für Vektordatenbanken Finanzierungen mit Bewertungen von über 700 Millionen Dollar. Was also macht Vektordatenbanken zu etwas Besonderem und warum erhalten sie eine solche Aufmerksamkeit?
Herkömmliche Datenbanken eignen sich zwar hervorragend für die Abfrage von Millionen von Datensätzen, haben aber Schwierigkeiten, die zunehmende Komplexität moderner Daten zu bewältigen. Da wir immer mehr Informationen in Formaten wie Bildern, Dokumenten und Audiodateien speichern, können herkömmliche Datenbanken die Effizienz und die geringe Latenzzeit nicht mehr aufrechterhalten. Mit anderen Worten: Die riesigen Mengen an unstrukturierten Daten, die wir erzeugen, erfordern einen Paradigmenwechsel und eine neue Art von Datenbankmanagementsystem.
Was sind Vektordatenbanken und wie funktionieren sie?
Bevor wir in die Welt der Vektordatenbanken eintauchen, ist es wichtig, das Konzept von Vektoren zu verstehen. In der Mathematik ist ein Vektor eine mathematische Einheit, die sowohl eine Länge als auch eine Richtung hat. Diese physikalische Größe wird oft als länglicher spitzer Pfeil im Raum dargestellt und wird zur Beschreibung von Kräften, Beschleunigungen und elektrischen oder magnetischen Feldern verwendet, die sowohl eine Länge als auch eine Richtung haben. In der Regel werden Vektoren durch eine Reihe von ganzen Zahlen ausgedrückt, die als Komponenten bezeichnet werden.
Eine Vektordatenbank speichert Daten als Vektoreinbettungen, d. h. eine Technik zur Übersetzung von Daten in numerische Vektoren, die wesentliche Eigenschaften der Daten erfassen. Diese Vektoren werden in einem hochdimensionalen Raum gespeichert, wobei jede Dimension ein eindeutiges Merkmal der Daten darstellt. Auf diese Weise kann die Datenbank mit geringer Latenz Datenelemente abrufen, die einem bestimmten Abfrageelement ähnlich sind, und zwar auf der Grundlage der Ähnlichkeit ihrer Vektoreinbettungen.
Betrachten wir als Beispiel eine Bildsuchmaschine. Wenn ein Benutzer ein Bild als Suchanfrage eingibt, wird das Bild in eine Vektoreinbettung umgewandelt, wobei jede Dimension des Vektors einem eindeutigen Merkmal des Bildes entspricht, z. B. Farbe, Textur oder Form. Die Datenbank führt dann eine Ähnlichkeitssuche in den Vektoreinbettungen aller gespeicherten Bilder durch, um die Ergebnisse zu ermitteln, die dem gesuchten Bild am ähnlichsten sind.
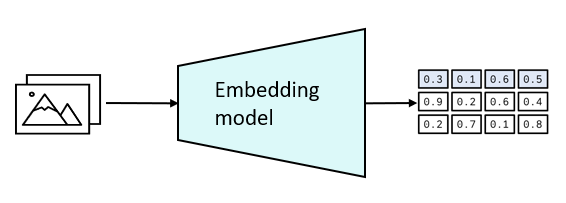
Um diese Einheiten im hochdimensionalen Raum sinnvoll zu speichern, werden verschiedene Machine-Learning-Algorithmen zur Klassifizierung der Daten eingesetzt. Das Ergebnis dieser Klassifizierung wird in verschiedenen Clustern und Gruppierungen gespeichert.
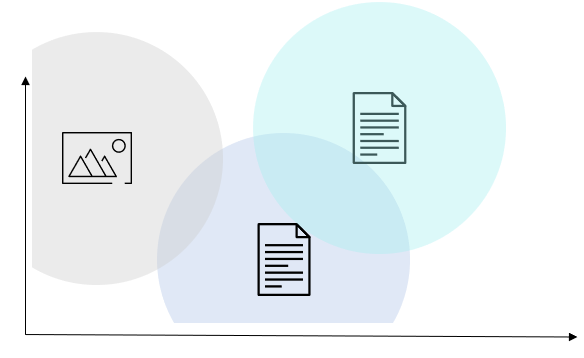
Vereinfacht ausgedrückt werden unstrukturierte Daten als Vektoren in verschiedenen Clustern gespeichert, was einen effizienten Vergleich zwischen zwei beliebigen Vektoren oder zwischen einem Vektor und einer Suchanfrage (wie eine umgekehrte Bildsuche im obigen Beispiel) ermöglicht.
Vorteile von Vektordatenbanken
Jahrelang reichte es aus, die zu speichernden Elemente mit Metadaten zu versehen, um komplexe Daten zu verarbeiten, warum also eine Vektordatenbank in Betracht ziehen? Die Vorteile von Vektordatenbanken werden beim Suchen und Vergleichen komplexer Daten deutlich.
Ähnlichkeitssuche
Mit Hilfe von Methoden, die den Abstand zwischen Vektoren in der Datenbank bestimmen, können Vektordatenbanken eine Ähnlichkeitssuche durchführen. Der euklidische Abstand und die Kosinusähnlichkeit sind zwei mathematische Formeln, die sich zur Bestimmung des Abstands zwischen zwei Vektoren verwenden lassen.
Bei einer Ähnlichkeitssuche wird ein Abfragevektor mit den in der Datenbank gespeicherten Vektoren verglichen, um festzustellen, welche Vektoren am ähnlichsten sind. Der Abstand zwischen dem Abfragevektor und jedem der anderen Vektoren in der Datenbank wird bestimmt.
Die Verwendung von Indizierungsstrategien trägt dazu bei, den Prozess der Ähnlichkeitssuche zu beschleunigen. Bei der Indizierung werden die Vektoren anhand von Attributen wie Länge oder Richtung in überschaubare Gruppen unterteilt. Infolgedessen kann der Suchalgorithmus eine große Menge an Daten in der Datenbank, die wahrscheinlich keine identischen Vektoren enthalten, schnell eliminieren.
Semantische Suche
Durch die Darstellung von Text als Vektoren unter Verwendung von Natural Processing Language (NLP)-Methoden sind Vektordatenbanken in der Lage, eine semantische Suche durchzuführen. Auf diese Weise kann die Datenbank beurteilen, wie semantisch ähnlich verschiedene Textdokumente oder Suchbegriffe sind.
NLP-Algorithmen verwenden Strategien wie Worteinbettungen, die Wörter oder Phrasen in mehrdimensionale Vektordarstellungen umwandeln, um Text als Vektoren darzustellen. Auf der Grundlage des Kontexts und des gemeinsamen Vorkommens von Wörtern in großen Textkörpern vermitteln die Vektordarstellungen von Wörtern und Phrasen deren Bedeutung.
Die Datenbank kann eine semantische Suche durchführen, indem sie die Ähnlichkeit zwischen den Vektoren bestimmt, sobald der Text als Vektoren dargestellt wurde. Hierfür kann die Ähnlichkeitssuche in Nicht-Text-Vektordatenbanken verwendet werden, ebenso wie Methoden wie die Kosinusähnlichkeit oder der euklidische Abstand.
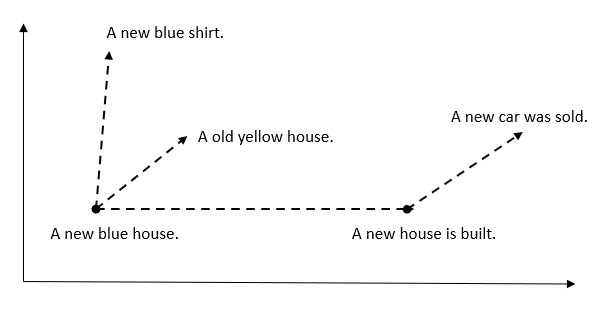
Sobald der Text in der Datenbank gespeichert ist, können zwei beliebige Vektoren, die Text darstellen, miteinander oder mit dem Vektor einer Suchanfrage verglichen werden. Der Vergleich erfolgt anhand von Ähnlichkeitsmetriken wie der Kosinusähnlichkeit oder dem euklidischen Abstand, die den Abstand oder Winkel zwischen den Vektoren messen. Je geringer der Abstand oder je kleiner der Winkel, desto ähnlicher sind die Texte. Im Folgenden wird vereinfacht dargestellt, wie Texte mit ähnlichem Kontext auf der Vektorskala nahe beieinander liegen, aber durch eine bestimmte Dimension unterschieden werden.
Erkennung von Anomalien
Durch den Einsatz von Machine-Learning-Methoden, mit deren Hilfe sich Muster und Ausreißer in den durch Vektoren dargestellten Daten finden lassen, können Vektordatenbanken Anomalien erkennen.
Clustering, bei dem ähnliche Vektoren auf der Grundlage ihrer Nähe oder Ähnlichkeit zusammengefasst werden, ist ein beliebter Ansatz zur Erkennung von Anomalien in Vektordatensätzen. Unterschiedliche Vektoren oder Ausreißer können durch Clustering ebenso gefunden werden wie Gruppen von Vektoren, die einander ähnlich sind.
Wer profitiert von Vektordatenbanken?
Wenn Sie sich fragen, ob eine Vektordatenbank für Ihren Anwendungsfall notwendig ist, ist die Antwort vielleicht nicht ganz einfach. Obwohl Vektordatenbanken im Vergleich zu herkömmlichen Datenbanken erweiterte Funktionen bieten, ist ihre jüngste Beliebtheit weitgehend auf ihre Kompatibilität mit Large Language Models (LLMs) zurückzuführen.
Wenn die meisten Ihrer Daten hauptsächlich strukturiert sind und keine erweiterten Funktionen für die Ähnlichkeitssuche erfordern, kann eine herkömmliche Datenbank ausreichend sein. Wenn Ihr Anwendungsfall jedoch die Verarbeitung großer Mengen unstrukturierter Daten und die Durchführung schneller Ähnlichkeitssuchen beinhaltet, könnte eine Vektordatenbank die bessere Wahl sein. Wenn dies der Fall ist, könnte jetzt der richtige Zeitpunkt sein, um den Umstieg auf Vektordatenbanken zu erwägen.
