
The amount and complexity of data is growing at the speed of light. This data comes in unstructured forms, like documents, graphics, or plain text. Many organizations want to profit from the available data but classifying complex data with metadata alone may no longer be sufficient. Vector databases might be a solution to this challenge.
Despite the significant development in database technologies that can handle terabytes of data with low latency, vector databases have been making waves recently. This year, three vector database startups received funding with valuations exceeding $700 million. So, what makes vector databases special and deserving of such attention?
While traditional databases excel at querying millions of records, they struggle to handle the increasing complexity of modern data. As we store more information in formats like images, documents, and audio, traditional databases can no longer maintain efficiency and low latency. In other words, the massive amounts of unstructured data we generate requires a paradigm shift and a new type of database management system.
What Are Vector Databases and How Do They Work
Before delving into the world of vector databases, it is essential to grasp the concept of vectors. In mathematics, a vector is a mathematical entity possessing both magnitude and direction. This physical quantity is often represented as an elongated, pointed arrow in space and is used to describe forces, accelerations, and electric or magnetic fields that have both magnitude and direction. Typically, vectors are expressed using a set of integers known as components.
A vector database stores data as vector embeddings, which is a technique of translating data into numerical vectors that capture essential properties of the data. These vectors are stored in a high-dimensional space, where each dimension represents a unique feature of the data. This allows the database to perform low-latency retrieval of data items that are like a given query item, based on the similarity of their vector embeddings.
To give an example, let’s consider an image search engine. When a user enters an image as a query, the image is converted into a vector embedding, with each dimension of the vector corresponding to a unique feature of the image, such as color, texture, or shape. The database then performs a similarity search on the vector embeddings of all stored images to return the most similar results to the query image.
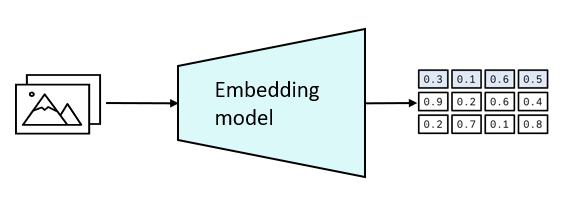
To effectively store these entities in a meaningful way within the high-dimensional space, various machine learning algorithms are employed to classify the data. The result of this classification is stored in different clusters and groupings.
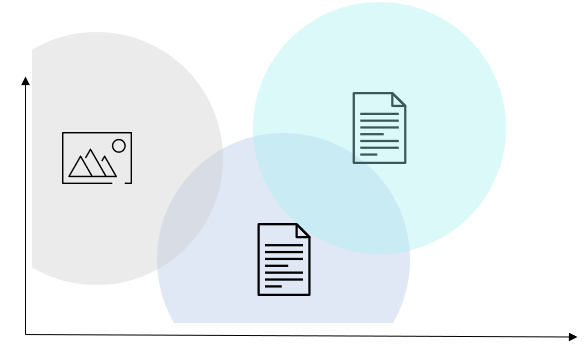
In simple terms, unstructured data is stored as vectors in different clusters, enabling an efficient comparison between any two vectors or between a vector and a search query (like a reverse image search in the example above).
Benefits of a Vector Database
For years, annotating to be stored elements with metadata was sufficient to handle complex data, so why even consider using a vector database?
Benefits of vector databases become apparent when searching and comparing complex data.
Similarity search
By utilizing methods that determine the distance between vectors in the database, vector databases may carry out similarity searches. The Euclidean distance and cosine similarity are two mathematical formulae that may be used to determine the distance between two vectors.
A query vector is compared to the vectors kept in the database during a similarity search to determine which vectors are the most similar. The distance between the query vector and each of the other vectors in the database is determined.
The use of indexing strategies helps speed up the similarity search process. The process of indexing entails dividing the vectors into more manageable groups according to attributes like magnitude or direction. As a result, a significant amount of data in the database that is unlikely to contain identical vectors may be swiftly eliminated by the search algorithm.
Semantic search
By representing text as vectors using natural language processing (NLP) methods, vector databases are able to do a semantic search. This enables the database to assess how semantically similar various text documents or search terms are.
NLP algorithms employ strategies like word embeddings, which convert words or phrases into multidimensional vector representations, to represent text as vectors. Based on their context and word co-occurrence in huge text corpora, these vector representations of words and phrases convey their meaning.
The database may do a semantic search by determining the similarity between the vectors once the text has been represented as vectors. Similarity search in non-text vector databases may be used for this, as well as methods like cosine similarity or Euclidean distance.
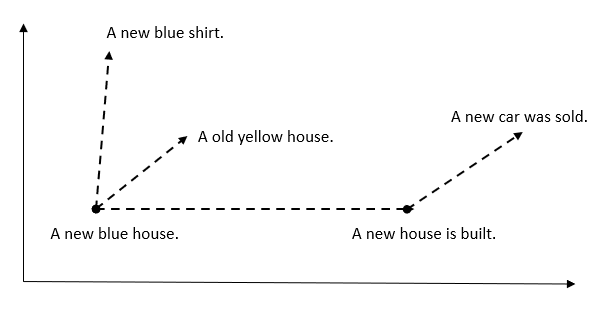
Once the text is stored in the database, any two vectors representing text can be compared to each other, or to the vector of a search query. The comparison is done using similarity metrics, such as cosine similarity or Euclidean distance, which measure the distance or angle between the vectors. The closer the distance or the smaller the angle, the more similar the texts are considered to be. The following is a simplified representation of how texts with a similar context lie close to each other on the vector scale but are distinguished by a particular dimension.
Anomaly detection
By using machine learning methods to find patterns and outliers in data represented by vectors, vector databases can detect anomalies.
Clustering, which groups similar vectors together based on their proximity or similarity, is a popular approach for detecting anomalies in vector datasets. Dissimilar vectors or outliers can be found by clustering as well as groups of vectors that are similar to each other.
Who Benefits From Vector Databases?
If you are wondering whether a vector database is necessary for your use case, the answer may not be straightforward. While vector databases offer advanced functionality over traditional databases, their recent popularity is largely due to their compatibility with Large Language Models (LLMs). If most of your data is mainly structured and does not require advanced similarity search capabilities, a traditional database may suffice. However, if your application involves processing large amounts of unstructured data and performing high-speed similarity searches, a vector database could be a better choice. In this case, now might be the right time to consider shifting to vector databases.
