
There is a strong competition among machine learning (ML) and data science platform providers, all claiming to possess a distinct edge in the digitalization marketplace. From Artificial Intelligence (AI), Data Science, Internet-of-Things (IoT), to Deep Learning and other technologies that are fueling business models and processes, we must make a sophisticated choice on our journey towards intelligent enterprise. SAP offers a unique data intelligence platform that supports such endeavor.
In these days SAP announced the SAP Data Intelligence platform with the goal to offer a coherent machine learning and data science foundation that leads your business to an intelligent enterprise evolution.
The vision of the intelligent enterprise is in the heart of the SAP strategy, to reach this goal, AI applications have to be delivered at scale. Ideally, this should be one integrated offering with one data science frontend and cover full lifecycle management – all integrated with SAP systems.
However, delivering these applications can be quite challenging and every stakeholder faces a different point of view –
- The CIO would deploy and scale data science or ML application at low cost and require a stable solution
- The Data Science Team would like to have a development environment which is compatible towards enterprise requirements, however, still with further exploration possibilities
- The final IT operation or DevOps team is focusing on re-usability, stable deployment and maintainability
SAP is aiming exactly at these three stakeholders with the goal to manage end-to-end machine learning scenarios within one system.
Camelot’s view on AI
We at Camelot highly appreciate this goal and in the past we continuously published articles to master professional data science around:
- Identifying value
- Visual analytics
- Microservices
- Overall importance of data science
In fact, the full CRISP cycle of identifying value, data preparation, model creation, service deployment and operation has been long deployed by Camelot in our data science-driven projects towards enterprise digitalization.
First step: EDA
Before any data science technique is implemented, one must perform an exploratory data analysis in order to gain first insights and potential complexity of the problem on hand, as described in Exploratory Data Analysis (EDA) an important step in data science. EDA is essential for a well-defined and structured data science project and it should be performed before any statistical or machine learning modeling phase. The main pillars of EDA are data cleaning, data preparation, data exploration, and data visualization. Since recently, we are actively using SAP Analytics Cloud as a main enterprise application for the data analysis visualization.
Second step: modeling stage
As the data is ready to be worked on, we turn to modeling stage. Machine Learning (ML) can deliver value to your corporation. That’s a fact. However, as mentioned in Data Science for insights finding, it is not a magic box and the usage of data science to solve your pain points should be closely related to your business knowledge and aligned with business experts. Their knowledge and experience are essential to gain insights from your data. Data Science tools, on the other hand, are critical for developing optimization models for your enterprise and correct interpretation of the results allows us to improve your business flow and generate value with ML.
Widely discussed: microservice architecture
We strongly believe that within the endeavor of a digital transformation, a significant change within enterprise IT Infrastructure will take place. Microservice architecture is probably the most widely discussed and adopted architecture pattern nowadays. With the rise of cloud-native architecture, software applications are now built as a collection of microservices, leveraging Docker or Kubernetes technologies. The significant change is the grouping around services instead of libraries, as outlined in Microservices business and technology level. In short, microservices-based architectures enable continuous delivery and deployment. A microservice should fulfill a customer need and its design is managed and owned by joint development and operation teams with a strong link to business units. It is all about purpose / value grouping instead of identical skill / functional grouping. So, almost all the enterprises are either practicing or trying to adopt microservices architecture.
Important: learning journey
As discussed in our most recent blog post The importance of a Data Science learning journey for your organization, the future of nearly all businesses is all about coping with digital transformation. New information technologies, ML applications, and operational technologies are exploding around us and bringing rapid change to what is possible in business. No one should expect business as usual for much longer.
New SAP platform
SAP will now address most of the problems by bundling different service offers into one integrated data science offering (see Figure 1).
The core components of the new platform will be around:
- SAP Data Hub with the goal to provide data sharing and orchestration which is based on Kubernetes
- SAP Predive Analytics with focus on operationalization and automation
- SAP Leonardo ML foundation providing managed ML services called via REST APIs
- SAP Hana ML as core in-memory data base enabling machine learning services and fast data management
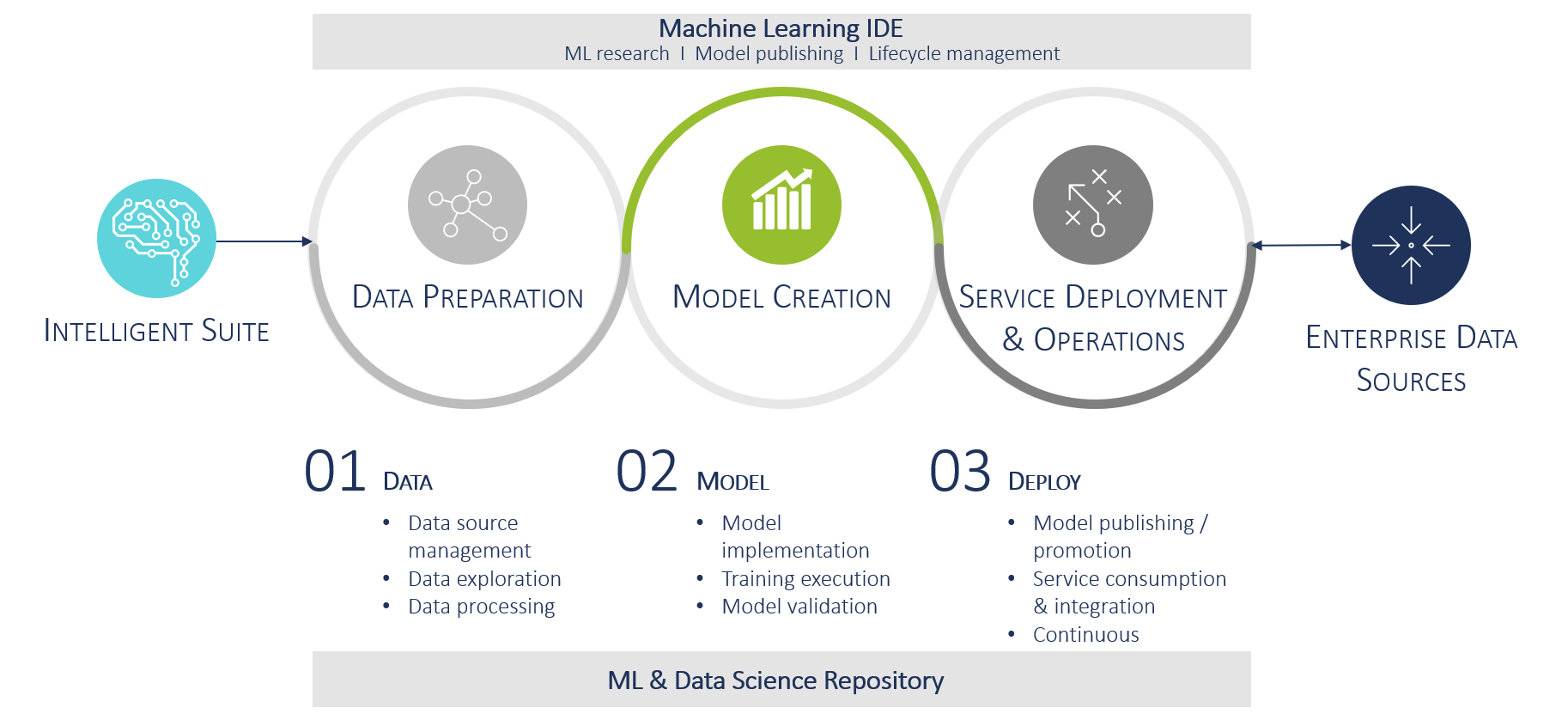
When looking at all aspects it becomes clear that this is not a light weight explorative framework, rather, it tackles the problem of full AI lifecycle management. A quick entry point for non-experts will be still difficult, especially with the promise towards so-called citizen data science ship not yet provided.
Still, we strongly believe that the direction and combination of the new offering is going into the right direction. Furthermore, Camelot will place there its first micro-services on this platform in the coming months. As SAP Gold Partner we will share our insights and experience with SAP and of course with our clients to support the fast progress of the overall applied data science endeavor.
We would like to thank Julija Mihalkina and Frank Kienle for their valuable contribution to this article.