
Data Catalogs enable a modern way of working with data, including features like glossaries or functionalities to collaborate across teams. They also help to establish new concepts of data management like data mesh and build the foundation for internal and external data sharing.
Common Challenges of Metadata Management
In our modern digital world, ever more businesses are built on data. Due to the increasing amount of data, the importance of generating insights and values out of it has become a game changing competitive advantage. Especially large and complex enterprises regularly face the question how to manage that amount of data. This blog sheds light on the common challenges of metadata management by answering the question which role data catalogs play in a data-driven world: Where can I find the data I need? When was the data created? Is the data valid? Who has access to the data? How is the data quality? Can I trust the data? What does the data mean? Which shape can I expect?
Without a well-defined metadata management framework and complementary tools in place, these questions often remain unsolved, or it takes a tremendous amount of time to answer them. Often, heterogeneous data landscapes with multiple systems where data is stored in different ways are the core of the problems. The missing governance along these data leads to bad data quality, loads of unused data sets or a high manual effort to update the different silos. This does not only lead to inefficient processes and higher costs, but also to employee dissatisfaction. Therefore, transparency throughout your data is needed to make it available for analytics and automation. The key to opening the door for value generation is the underlying metadata, often called “Data about Data”. Metadata provides various information to the different user groups to understand the source, the drivers, the content, the usage, and technical details of data. One key metadata management tool for creating transparency and trust in data is the data catalog
What Is a Data Catalog?
A data catalog is the organized inventory of distributed datasets of an enterprise, including the collection of metadata and various capabilities useful for different teams. It enables professionals with diverse roles to manage, access, and process the data in order to extract the value of it that they need. Furthermore, it bridges the gap between data sources and data users. By enabling the availability of data for everyone throughout the company, data catalogs create the foundation for extracting value from the data through analytics, data science and machine learning.
Main Features of Data Catalogs
We already introduced the concept in this blog post on data catalogs. In the following, we will have a closer look at the main capabilities and features of most available data catalog solutions:
- A glossary is the dictionary of a catalog, where the meaning of the terms, attributes, or tables is defined and the relations between them are shown. This way, even the teams which do not know the data can grasp the business meaning of the datasets.
- While the glossary provides clarity of the business terms, metadata management gives insights on the data itself. Metadata is the “logs” kept on the actual data, including how it is structured, where it comes from and how it changes. Keeping this information can be crucial for the teams to have transparency about their data.
- Data lineage is the functionality for tracking the origins of a dataset. The feature makes information on where the dataset comes from, how it evolved and what was modified available to the user.
- The search function helps people to find relevant data quickly, boosting the efficiency of the analysts’ tasks.
- Data catalogs have collaboration features to support the cooperation of the teams by enabling comments in a dataset, rating them, and preparing wiki-like articles. At the same time, these collaboration features are also a way of providing crowd-sourced metadata about the data and its quality. In this way, data catalogs are not only relevant for internal purposes, but also build the foundation for external data sharing.
Add-ons: ML and AI Features in Data Catalogs
Some data catalog products also combine these functionalities with machine learning and artificial intelligence in order to automate and enhance aspects of data governance. Possible scenarios are, for example, the use of behavioral analysis or the automation of tasks like profiling and classifying. As a result, these techniques help to increase data quality, accuracy, and efficiency to enable companies to cope with the increasing amount of data to be managed.
Anonymizing Data and Integration of Data Sources
Data catalogs can also help to ensure the protection of sensitive data by supporting role-based access, anonymizing data before cataloging as well as implementing data policies. Lastly, the data catalog solutions on the market currently usually offer pre-built connectors to integrate data sources of the most commonly used types with minimum configuration effort. A modern catalog connects all components in an intelligent platform and is developed on big data or cloud infrastructure to allow scalability. The most important features of a modern data catalog are summarized in figure 1.
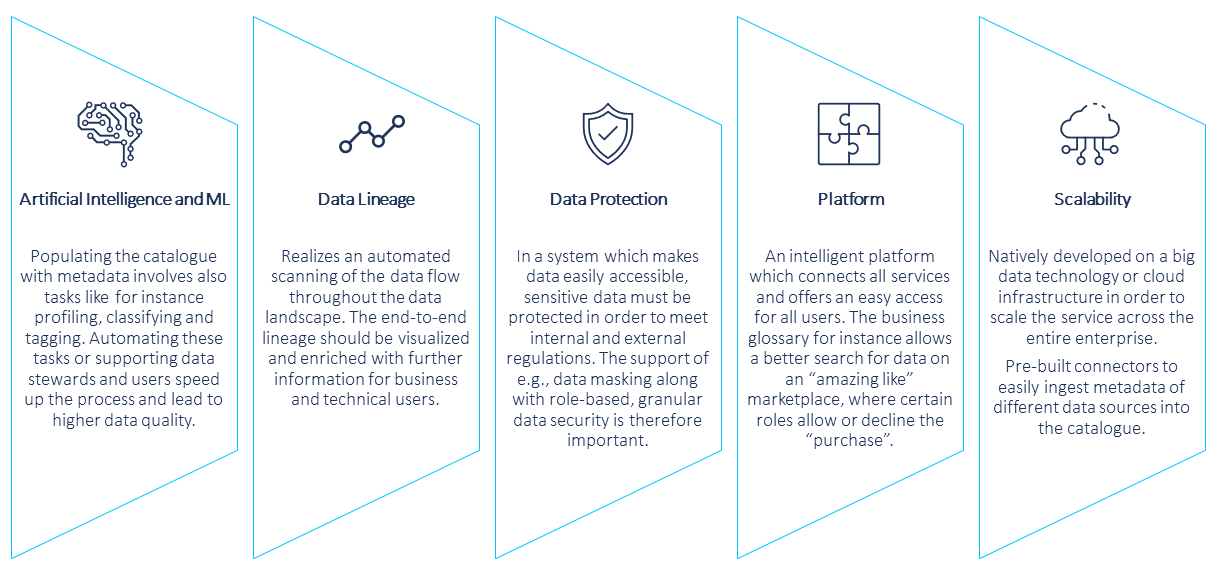
Data Catalog as an Enabler in a Data-Driven World
In a classical approach, data engineers and data scientists are usually the ones handling the data. However, they mostly lack the business perspective and the context of the data. In order to accurately analyze and unlock the real potential of data, the business perspective is a must. Therefore, the accessibility for all teams that can derive value from the data must be enabled by making the data visible and understandable. With this, we are talking about “data democratization”. Data catalogs are great enablers at this point because of all the features they provide, like the metadata, glossary, or functionalities to collaborate across teams. The core concept of a data catalog is depicted in figure 2.
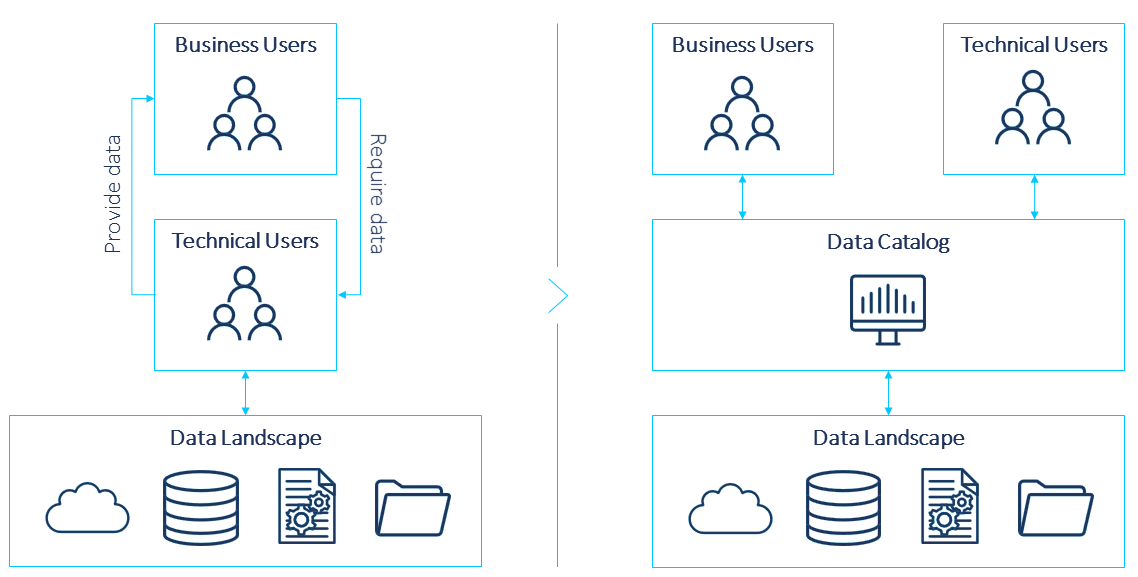
Data Catalog for Data Mesh
As mentioned before, the core features of data catalogs are means to provide attributes of data products that are a prerequisite of data mesh. This new architectural approach has been a hot topic as it applies organizational measures to overcome the bottlenecks of traditional data architectures like data warehouse or data lakes. For a more detailed introduction, please visit our blog post on data mesh. It moves away from centralized data management to a decentralized domain-based approach, especially for analytics data assets. Cross-functional teams, which are most familiar with the data, are made responsible to provide data as a product to other parties throughout the enterprise.
By doing so, data mesh intends to overcome the necessity of a central team of technical experts that has to become active for the provision of data to consumers. It rather relies on a central self-serve platform making data products findable, accessible, interoperable, and reusable, also known as the FAIR principle. On the one hand, the platform enables data product owners to create data products with a high level of interoperability and inter-connectivity. On the other hand, it allows consumers to serve themselves with the data they need and understand the data. With a data catalog as a crucial part of the infrastructure for a data mesh, it becomes a key enabler for internal and external data sharing.
Data Catalog: No One-Size-Fits-All-Approach
In the end, a data catalog always needs to be a customer-specific tool selection or combination of tools because the solutions on the market have all their own strengths and focuses. Thus, there is no comprehensive tool which fits all customer needs and the reason why it is necessary to select the right tool based on the customer specific requirements. For more information, please get in touch with us.
The authors would like to thank Yosr Cheikh and Gregor Titze, consultants for data and analytics, for their contributions to this article.
