
Automation of document processing is among the hardest digital transformation initiatives due to its highly customizable nature. While some organizations have tried using traditional optical character recognition (OCR) solutions to automate document processing, many of them have found that legacy OCR-based approaches to document processing are error-prone and difficult to scale. As a result, they almost always end up reverting to human reviews. Manual data extraction from documents is time consuming, creates gigantic overheads, and is completely exposed to human error. It further generates frustration in employees due to repetitive tasks and most importantly prevents them from offering actual value to your organization. The CAMELOT Automated Data Extraction Tool (CADET) offers an automated cross-industry solution including streamlined information extraction and analysis of any physical document and integrates the extracted data into industry standard systems such as SAP ERP.
Repetitive, time consuming, and insufficient data quality
Quality and safety of data is of utmost importance. This is especially true in industries such as pharma, biotechnology, or chemistry, where lives are dependent on the developed and produced products. Consequently, it is important that the product data quality always remains high. It is complex to manage given the handoffs that happen between different vendors within the complex supply chain network. An example of this problem is the quality check of materials (i.e., certificates of analysis) in the pharma industry.
Extensive quality checks are performed for specified material characteristics to ensure the compliance with pre-defined quality standards. The quality check results are manually introduced into the ERP system based on hand-written quality certificate forms. Taking the example of one of our chemical & life sciences customers, this customer processes about 8,000 monthly documents, with an average processing time of 20 minutes per document. This process consumes a total of 160,000 minutes every month to our customer, that accounts for about 17 full time employees performing only the task of manually entering this data into the system. Assuming a salary of 50,000 EUR, this task would require close to a million EUR per year! Moreover, the data quality would be at risk since manual data replication is one of the most error-prone practices in current business processes.
Our solution enables an automated data extraction and data system maintenance that will completely transform the current paradigm of manually maintained entries. It provides a standard solution for harmonized input handling and automated extraction and digitization of information, additionally validating the extracted information against various external/internal sources and can be customized according to any industry and process requirements.
Customizable data extraction with several cross-industry use cases
At CAMELOT, we provide flexible use cases that are based on projects in different industries. CADET is powered by Amazon Textract to convert the documents into text that is understood by the computer, using OCR. Here, we provide the summary of the largest projects with CADET.
Extraction of data using customer-defined templates
Does your company face the data extraction challenge of thousands of documents with similar structure that need to be manually reviewed? With structured data, you upload a form to our intuitive web application CADET. You only must define the places of the document where you expect to find different data fields. We achieved at least 92 percent accuracy in handwritten forms in our previous projects using the structured data extraction, thanks to the unique combination of Amazon Textract and our post-processing automated validation.
Material specifications for suppliers
If you are a large company that works with several hundreds or thousands of suppliers, this might be your use case. One of our customers faced the issue of receiving over 10,000 material specifications from different suppliers every month. Each supplier sends their own material specification format and measurements. Each specification might appear in any part of the document and not all the specifications are present in every document.
We input the text extracted by Amazon Textract into our own machine learning algorithm that can correctly identify material properties, their measurements, and units (if applied) with an accuracy of 89 percent (+/-5 percent). This translates in roughly 27 out of 30 correct data entries extracted by document. The user interface allows users later to validate the data extraction from CADET. To facilitate this task, CADET outputs a probability of every data entry being correct.
Batch report digitization in the biotech industry
Improving processes in the biotechnological industry needs the analysis of vast amounts of data. Currently, most biotech companies include the data reports manually into Excel sheets to then analyze them. This generates an enormous overhead that prevents them from a data analysis that provides reals value. Thanks to CAMELOT’s CADET, biotechnical companies are now able to automate the data extraction, obtaining the data in the correct forms and schemas with an extraction accuracy above 92 percent, including handwritten forms.
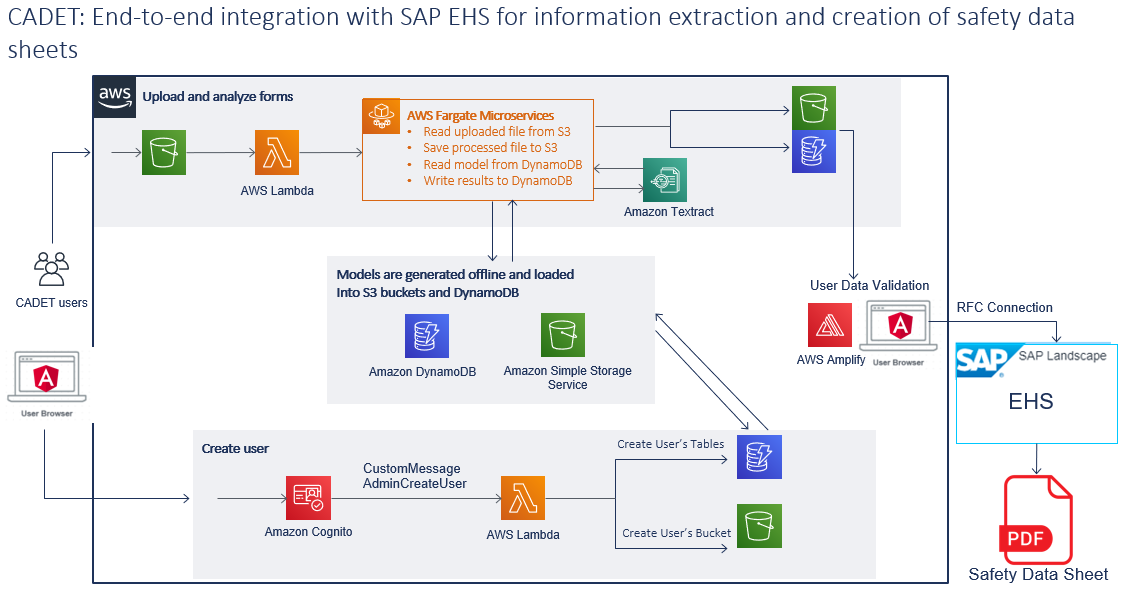
End-2-End Integration with SAP ERP Systems for Safety Data Sheets
Safety is key. Safety data sheets are mandatory in most chemical industry settings and closely regulated by several compliance standards. Furthermore, these data sheets must be generated in the language of the country of destination. To support with data extraction and document creation for safety data sheets, we replicated this process with CADET for two customers in the chemical industry.
Next to data extraction, our solution covers the entire end-to-end process of data digitization. Thanks to CAMELOT’s experience with SAP, we can integrate our data extraction solutions with different ERP systems.
In the case of safety data sheets, the SAP relevant system is the “SAP Environment, Health, and Safety Management” (EHS). The EHS system contains the standard regulations to generate safety data sheets out of the inputs to the system. We use the data extracted with CADET as an input to generate the required safety data sheets using the EHS system. We achieve this thanks to an RFC connection to the EHS system and the required ABAP code to generate the safety data sheet.
This solution is under current development. Currently we can successfully extract information from the sections 1, 2, 8, 9, and 14 of the safety data sheets and successfully generate safety data sheets. We plan to extend this to the entire document and make it available as SaaS in AWS by the end of 2022.
Data quality is a must in the age of data
Our customers belong to industries where data quality and integrity is key. Therefore, we offer our unique data validation services to help these customers. This data validation service is a post-processing algorithm that improves the already superb data extraction quality provided by Amazon Textract and our AI algorithms. We provide our customers with the option of further improving their data accuracy by cross-checking it against their master database. This feature increases by 30% the extraction accuracies To give some examples: An entry reading “Bermany” in the field “Country “would be normalized to “Germany”. If you have a ZIP code 69115, the data base gives a ZIP code of 69715 for this customer, we these discrepancies can be validated automatically for you.
Why Amazon Textract?
In our experience, Amazon Textract is the best OCR solution among the largest cloud providers. It does not only extract text from images with high accuracy, but it also does an unmatched job at extracting structures such as tables and forms from image documents, offering an amazing flexibility to our algorithms.
When we faced our first data extraction project two years ago, our first step was to compare the big vendors in the OCR field. At that point, AWS was doing well at font-text detection but was less accurate in handwritten text extraction than the competitors. However, in just a year, Amazon Textract has undergone an amazing development phase, so that it now matches, and even surpasses, the competitors’ data extraction quality. This shows that AWS in general, and Amazon Textract in particular, are services that improve themselves continuously. A continuous development brings new features to the market and constantly increases quality. Also, AWS actively seek feedback from customers and partners on their experiences and areas of industry expertise, which feeds directly into the roadmap for new features. In our opinion, this is an even stronger reason for choosing Amazon Textract.
The most important features of Amazon Textract for our extraction tool are the table extraction, the handwritten text extraction, and the language support which is a must for us in most of the western European languages. Amazon Textract is also robust, fast, and offers an astonishingly easy to use API in several programming languages (English, German, Portuguese, French, Italian, Spanish, …). The structure of the response data model has such detail that allows us to use it easily and flexibly as input to our high-end AI algorithms to generate the data extraction of any kind of document.
Find your solution
At CAMELOT, we have faced the automated data extraction problem several times and in different industries. Every single project has improved our knowledge and experience on the topic. Thanks to the broad experience obtained in the last years, we provide a cross-industry, highly accurate, and robust tool to automate the data extraction for our customers.
We would like to thank Jorge Abreu Vicente and Stefan Morgenweck for their valuable contribution to this article.