
Manual system maintenance of information based on paper forms is an activity that is part of everyday corporate life in many companies regardless of the size or the industry of the enterprise. This manual work is time consuming and creates a huge overhead. At the same time, manual maintenance of the results may also lead to human errors and employee dissatisfaction, due to the tedious process of entering the data. Camelot Automated Data Extraction Tool (CADET) offers an automated cross-industry solution including streamlined information extraction and validation of any physical document.
Especially in the pharmaceutical industry quality and safety of data is of utmost importance, as often lives directly rely on the developed and produced products. For that reason, materials delivered by suppliers are closely monitored and extensive quality checks are performed for specified material characteristics to ensure the compliance with defined quality standards. The quality check results are then entered manually in the company’s ERP system based on filled-out quality certificate forms, also known as certificate of analysis (CoA). Assuming there are 3,000 forms per month, which take around 30 minutes each to manually be entered into the company system, this process of inputting the data by itself consumes around 90,000 minutes. That is equal to having 9 full-time employees solely entering data.
Our solution enables an automated evaluation and system maintenance of manually maintained entries. It provides a standard solution for harmonized input handling and automated extraction and digitization of information, additionally validating the extracted information against various external sources, and can be customized according to any industry and process requirements.
Extraction of structured data via self-defined templates
The solution allows the user to create document templates by uploading an existing, structured document and drawing in bounding boxes, to indicate where labels and their corresponding values are located in the document. This initial template setup enables the user to generate a data extraction and processing pipeline for specified documents by easily defining field areas as well as expected field entries. For each field, the user has the option to define if the extracted data will be validated against a certain data source, has to adhere to business rules or needs to match a certain format, e.g., date, number or text. Information of uploaded documents is extracted via iOCR and values are validated by the user before they are processed further in the system.
Extraction of unstructured data leveraging machine learning models
In contrast to the structured document feature, the unstructured document feature does not require an initial setup of a document template by the user. This functionality is especially relevant when document formats and layouts are changing from document to document, e.g., when receiving non-standardized forms from various customers or suppliers. Leveraging machine learning (ML) models, the feature is compatible with any form, format or structure (printed or handwritten text). Therefore, this is the more flexible option, although it comes with the prerequisite that users and enterprises will need to train their own data on it, so the application will be able to extract data from unstructured forms. There are currently two built in use cases in place: Quality assurance and material specification sheets for the pharmaceutical industry.
Benefits
Improve data quality
Digitizing the manual data input process and automating data extraction lead to better data quality as well as better insights and analytics. As the user validates the accuracy of the algorithm’s results in the application, the solution minimizes human errors during the process.
Increase efficiency
Accelerating the process of entering data into the system increases the number of documents that can be processed by an employee. Those efficiency gains reduce the time spent on repetitive tasks and free up qualified resources to focus on more sophisticated and demanding .
Cover end-to-end processes
Based on the SAP® Data Intelligence cloud service, the solution automates the process of feeding data from standardized forms or documents to clients’ ECC or database systems by defining data semantics.
Technical information
Based on the uploaded structured or unstructured document templates, the CADET application will automatically launch a process to extract text from images with iOCR, which is described below:
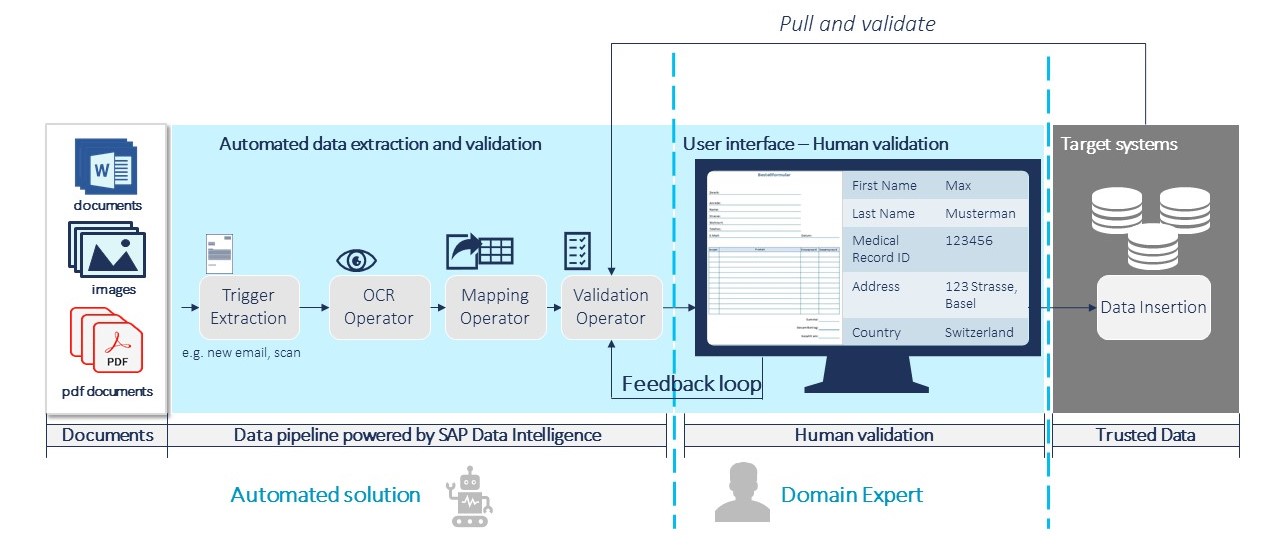
Once the text is extracted, the CADET algorithms enter the game. For structured documents the application is performing a direct key-value matching with the iOCR output based on the defined coordinates and fields. In comparison, unstructured documents are processed leveraging advanced machine learning algorithms to identify key-value pairs in the iOCR output. Results will be enhanced by an automated validation layer that solves possible typos and then sends information to an Angular frontend. In the frontend, the user is able to validate and correct possible wrong entries, which the algorithm is explicitly highlighting.
Want to learn more?
You want to learn more about Camelot’s Data Intelligence solutions? Check out the following information or visit us:
- Customer Use Case Evonik
- INTELLIGENT RULE MINING SOLUTION
Interested? Contact us directly via dataintelligence@camelot-group.com.