
Manuelle Systempflege von Informationen auf Basis von Papierformularen ist in vielen Unternehmen Teil des Arbeitsalltags, unabhängig von Größe oder Branche des Unternehmens. Diese manuelle Arbeit ist zeitaufwendig und verursacht einen großen Mehraufwand. Zusätzlich kann die manuelle Verwaltung der Ergebnisse aufgrund des sehr mühsamen Prozesses der Dateneingabe zu menschlichen Fehlern und Mitarbeiterunzufriedenheit führen. Das Camelot Automated Data Extraction Tool (CADET) bietet eine automatisierte, branchenübergreifende Lösung einschließlich optimierter Informationsextraktion und der Validierungsmöglichkeit jedes physischen Dokuments.
Insbesondere in der Pharmaindustrie sind Qualität und Sicherheit der Daten von äußerster Wichtigkeit, da oft Menschenleben von den entwickelten und hergestellten Produkten abhängen. Aus diesem Grund werden von Lieferanten gelieferte Materialien streng überwacht und umfassende Qualitätskontrollen auf spezifische materielle Eigenschaften durchgeführt, um die Einhaltung definierter Qualitätsstandards sicherzustellen. Die Ergebnisse der Qualitätskontrollen werden dann auf Basis von ausgefüllten Qualitätszeugnissen, auch Certificate of Analysis (CoA) genannt, manuell in das ERP-System des Unternehmens eingegeben. Ausgehend von 3.000 Formularen pro Monat, von denen jedes 30 Minuten für die manuelle Eingabe in das Unternehmenssystem benötigt, kommt allein der Prozess der Dateneingabe auf etwa 90.000 Minuten. Das entspricht 9 Mitarbeitern in Vollzeit, die ausschließlich Daten eingeben.
Unsere Lösung ermöglicht eine automatisierte Auswertung und Systempflege der manuellen Einträge. Sie bietet eine Standard-Lösung für eine harmonisierte Eingabeverwaltung und automatisierte Extraktion und Digitalisierung von Informationen, wobei die extrahierten Informationen zusätzlich gegenüber diversen externen Quellen validiert werden. Die Lösung kann entsprechend jeder Branche und Prozessanforderung angepasst werden.
Extraktion strukturierter Daten über selbst definierte Templates
Die Lösung ermöglicht dem Nutzer, Dokumentvorlagen (Templates) zu erstellen, indem ein bestehendes, strukturiertes Dokument hochgeladen wird und Begrenzungsrahmen eingezeichnet werden, um anzuzeigen, wo im Dokument sich Feldbereiche und deren jeweilige Werte befinden. Diese erstmalige Einrichtung des Templates ermöglicht dem Nutzer, eine Pipeline für Datenextraktion und Verarbeitung für bestimmte Dokumente zu erstellen, indem Feldbereiche und erwartete Feldeinträge in einfacher Weise definiert werden. Der Nutzer kann für jedes Feld festlegen, ob die extrahierten Daten gegenüber einer bestimmten Datenquelle validiert werden, sich an Geschäftsregeln halten oder ein bestimmtes Format wie z.B. Datum, Nummer oder Text erfüllen müssen. Die Informationen der hochgeladenen Dokumente werden über iOCR extrahiert und die Werte werden durch den Nutzer validiert, bevor diese im System weiterverarbeitet werden.
Extraktion unstrukturierter Daten mit Machine Learning-Modellen
Im Gegensatz zu der Funktion für strukturierte Dokumente benötigt die Funktion für unstrukturierte Dokumente keine Ersteinrichtung eines Dokument-Templates durch den Nutzer. Diese Funktion ist insbesondere dann relevant, wenn Dokumentformate und -Layouts sich von Dokument zu Dokument ändern, z. B. bei Erhalt nicht standardisierter Formulare von verschiedenen Kunden oder Lieferanten. Durch die Nutzung von Machine Learining-Modellen (ML-Modellen) ist die Funktion mit jedem Formular, Format oder jeder Struktur (gedruckter oder handgeschriebener Text) kompatibel. Daher handelt es sich um die flexiblere Option, obwohl sie voraussetzt, dass Nutzer und Unternehmen ihre eigenen Daten verwenden müssen, um das System zu „trainieren“, damit die Anwendung in der Lage ist, Daten aus unstrukturierten Formularen zu extrahieren. Aktuell gibt es zwei integrierte Anwendungsfälle: Blätter zur Qualitätssicherung und zur Materialspezifizierung für die Pharmaindustrie.
Vorteile
Verbesserung der Datenqualität
Die Digitalisierung des manuellen Dateneingabeprozesses und die Automatisierung der Datenextraktion führt zu einer besseren Datenqualität, sowie zu besseren Erkenntnisse und Analysemöglichkeiten. Da der Nutzer die Qualität der Ergebnisse des Algorithmus in der Anwendung validiert, minimiert die Lösung menschliche Fehler während des manuellen Eingabeprozesses.
Effizienz steigern
Die Beschleunigung des Prozesses der Dateneingabe in das System erhöht die Anzahl der Dokumente, die von einem Mitarbeiter verarbeitet werden können. Dieser Effizienzgewinn reduziert den Zeitaufwand für repetitive Aufgaben und setzt qualifizierte Ressourcen frei, sich auf differenziertere und anspruchsvollere Aufgaben zu konzentrieren.
End-to-End-Prozesse abdecken
Auf Basis des SAP Data Intelligence Cloud Services automatisiert die Lösung den Prozess der Einspeisung von Daten aus standardisierten Formularen oder Dokumenten in das ECC- oder Datenbanksystem des Kunden durch Definition der Datensemantik.
Technische Informationen
Auf Grundlage der hochgeladenen strukturierten oder unstrukturierten Dokument-Templates, startet die CADET-Anwendung automatisch einen Prozess, Text aus den Bildern mit Hilfe von iOCR zu extrahieren, was unten beschrieben wird:
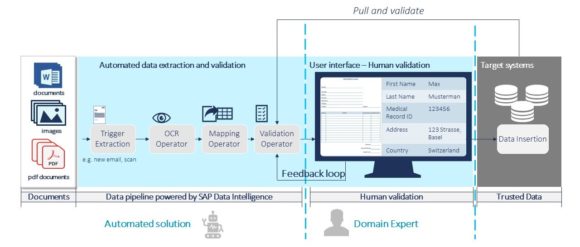
Sobald der Text extrahiert ist, kommen die CADET-Algorithmen ins Spiel. Für strukturierte Dokumente führt die Anwendung einen direkten Abgleich der wichtigsten Werte mit der iOCR-Ausgabe auf Basis der festgelegten Koordinaten und Felder durch. Im Vergleich dazu werden unstrukturierte Dokumente mit fortschrittlichen Algorithmen des Machine Learnings verarbeitet, um wichtige Wertpaare in der iOCR-Ausgabe zu identifizieren. Die Ergebnisse werden durch eine automatisierte Validierungsschicht verstärkt, die mögliche Tippfehler auflöst und die Informationen dann an ein Angular-Front-End sendet. Im Front-End kann der Nutzer mögliche falsche Einträge validieren und korrigieren, die der Algorithmus speziell hervorhebt.
Sie möchten mehr erfahren?
Sie möchten mehr über die Data-Intelligence-Lösungen von Camelot erfahren? Lesen Sie die folgenden Informationen oder besuchen Sie uns unter:
- Kunden-Anwendungsfall Evonik
- INTELLIGENTE RULE MINING-LÖSUNG
Interessiert? Sprechen Sie uns direkt an über dataintelligence@camelot-group.com.
