
Data virtualization is a concept in data management which will gain more importance within the next few years. It enables data integration across an organization, simplifies the IT infrastructure and builds a valuable foundation for leveraging data in business use cases. Why is data virtualization on the rise and why is it often one of the best (hybrid) solutions for data integration nowadays? How can it be implemented and what challenges might arise?
With the increasing number of data and also data sources, it is important to ensure that data is complete, correct, comprehensive, secure, structured and connected. That is where data virtualization comes into play: although the wording around data virtualization is difficult and the term seems to be blurry, it can be described as a concept for data management and data integration. The goal is to put an end to an increasing number of data silos where data is isolated from other parts of the organization. After the successful implementation, it enables the access, administration, and provision of data.
Data virtualization is implemented to improve and simplify the IT infrastructure and architecture as well as governance and compliance. It is also a valuable lever to promote data mining, predictive analytics, AI, and self-service analytics since the access to a large number of datasets from various data sources is simplified and accelerated.
ETL processes, their challenges, and an alternative approach
The aim of data management is to achieve an upward stability (data usage) and downward flexibility (data sources). It is desirable to create an integrated view of data from diverse source systems. In this context, data warehousing is often the well-known solution using ETL processes to make data available. ETL stands for extract, transform and load. It refers to the process of transferring data from one location to another while transforming the data. With this procedure, the data is replicated and restored in a physical data warehouse.
Although ETL is an important and often used process to integrate data, it is not flawless. For example, storage space is claimed when replicating and relocating the data which generates cost. Furthermore, moving data around physically is always a risk and comes with certain security concerns.
Hence, the question arises if, in some use cases, there is another approach to integrate and aggregate data: data virtualization. It cannot substitute ETL completely, but it is a great concept for many use cases or at least a good hybrid solution for data integration together with ETL.
Data virtualization: the concept
The virtualization layer and how it is built
To visualize the concept of data virtualization, it can be described as a virtual layer or a platform. It sometimes is referred to as a logical data lake (term of raw data) that lies between the variety of data sources and data consumers (as depicted in figure 1). With the implementation of this layer, it doesn’t matter if data is stored in various locations, across multiple data warehouses or various file formats. Data consumers don’t need to know exactly where the data is located physically and how it is organized at the source level, whether on premise or in the cloud.
Data virtualization enables access to real-time data. It is available to users from a single access point without effort and without significant time delays for purposes like reporting, analyzing, visualizing or other business intelligence processes.
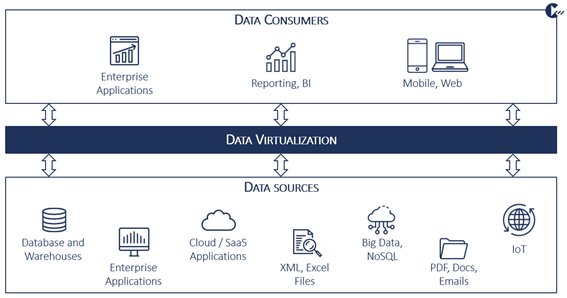
For implementing data virtualization, a data catalog is needed. The data virtualization data catalog may not to be mistaken with the descriptive catalog that is built with data governance tools to have a comprehensive inventory overview available, but an organization wide directory of available datasets. It is used as an internal “data marketplace” and consists of metadata. Data virtualization, which enables integration and delivery, then provides the possibility to browse this catalog – it is a virtual data connector as-a-service.
Using transformation to build a logical data warehouse.
The virtual layer enables the organization of data in different virtual schemes and virtual views, which would then be a logical data model. Data users can enrich the raw data from the source systems with the organization’s business logic. They have access to the desired modified datasets without having to store them physically. After connecting, transforming, and organizing the raw data, the logical data lake becomes a logical data warehouse.
Common data warehouses are not obsolete, but a virtual layer can be built on top of them, if the use case and the architecture allow it, to integrate data from those warehouses. It is the next generation data warehouse.
Delimitation of ETL and access.
Summed up, the unified data access layer or logical data warehouse is the non-physical “storage” of the organization’s information. With data virtualization, data is neither replicated nor moved so data virtualization does not persist data from the source systems. It simply stores metadata to feed the virtual views.
The logical data warehouse can be accessed with the help of data virtualization at a single access point with SQL queries, REST API requests or other common retrieval methods. There is no risk of accidentally manipulating the real data – the single source of truth stays untouched.
Implementation of data virtualization and presentation of some market players
At a high level, there are two possibilities to implement data virtualization in an organization.
- “Built-in” data virtualization solutions: It can be achieved e.g., with Microsoft Polybase (function in SQL Server 2019) or with SAP Smart Data Access. Both features for data virtualization enable the single point of access to a virtual layer.
- Commercial data virtualization solutions: Some important market players which offer data virtualization software are Denodo, IBM Watson Query, Data Virtuality or SAP Data Warehouse Cloud. Data Virtuality combine ETL with data virtualization as well as SAP DWC. SAP DWC enables which enables integrating different (ETL) tools and applications via native integration and virtualization functionalities.
In both cases, the implemented solution offers a search field to search the logical data warehouse for description, owner, or type. Further, if it is of interest, the location of the data is available, and any transformation that was applied in the virtual data layer before the data view was delivered. Data catalogs which serve as an inventory overview are integrated in the software as well as caching possibilities to improve performance. Depending on the tool there are all sorts of extra features to improve the data architecture, performance, or access of the virtual platform.
Challenges with the implementation of data virtualization
There are some challenges one needs to address when implementing data virtualization:
- Setting up data virtualization means a high initial investment to prepare servers and storage. Also, with the usage of external tools, the monthly investment can become costly.
- With built-in data virtualization options, the implementation highly depends on versions of existing software and IT architecture. It is not guaranteed that it can be implemented with e.g., SAP SDA.
- No matter if built-in solution or bought application: If many users want to access the virtual data, some performance problems might arise. In this case, it makes sense to think about returning to ETL.
- Data cleansing, mapping and transformation are still complex in the layer.
This article gave you an overview of what data virtualization is and how it is applied within an organization’s existing IT landscape. In most cases, the implementation is a high investment, and it does not solve all existing data management problems.
Nevertheless, when data management basics are already in place, the successful implementation will bring large improvements to organizations in the area of IT architecture, governance and compliance. Further, the implementation enables the simplification and acceleration of data access. That in turn enables data users from across an organization to concentrate on the evaluation of data to create added value for the company.
We from CAMELOT offer a holistic approach for data management and data virtualization and can support organizations with our experience during different stages of exploration and implementation. In case of open questions that you wish to discuss or for further information please get in touch with us.
