
Business rules are a fundamental element of the organizational data management process. Capturing these rules allows an organization to define data constraints and directives, gather insights over the data structure and serve as a base for several applications. In this blog post we will explain what exactly business rules are, how they are mined, and in which use cases your organization could leverage them.
Business rules are constraints or directives that apply to an organization’s data. They describe organizational structure, regulate and restrict organizational activities. Capturing the business rules of organizations is commonly done manually, which is a time-consuming and cumbersome task. By leveraging the capabilities of association rule mining algorithms, organizations can derive these business rules from their data automatically. These algorithms are designated to execute on computer clusters, allowing for numerous rules with high complexity to be uncovered.
What is Association Rule Mining?
Association rule mining is a simple, yet powerful technique utilized for discovering hidden patterns between attributes in large datasets. Association rule mining methods are commonly used for market basket analyses. For the customers’ shopping behavior, the algorithm identifies products that are commonly bought together and translates these frequent item sets to rules. This information can be utilized for the placement of products next to each other, if they are often bought together. Another example is the list of products suggested to online shoppers when they are viewing a product. There are many more steps in a company’s data management processes where rule mining will add value, as in exploring the data structure, supporting forms fields population with predictions and rule compliance check across multiple data sources.
The rule mining algorithm derives association rules from any relational data. The mined rules represent the probability of occurrence of a specific value given the known presence of other values. The derived set of rules are in the form of IF-THEN (also named: Antecedent – Consequent) statements. Each of the derived rules can be quantified by two essential metrics:
- Support – Indicates how frequent a rule is in the given dataset;
- Confidence – Indicates the probability of finding the value B given that we already have the value A.

Figure 1: Formulas for Calculating Support and Confidence Metrics
The extracted rules will have the following structure: A ⇒ B (Support: 50%, Confidence: 90%)
This rule informs us based on the given data: Given the value A is found in a data entry, there is a 90% chance of also finding B in the same data entry, with this item set occurring in 50% of all data entries in the entire data set.
Market Basket Analysis Example
To understand the concept of association rule mining, we will use a classical market basket analysis example. We have a shop selling six items: wine, pears, hamburger, cheese, ice cream and cherries. We have five transactions representing the shopping basket of five different customers. The first customer bought [hamburger, cheese] the second customer bought [hamburger, cherries, wine, ice cream] and so on. By using the formulas given above we extract a set of exemplary rules.
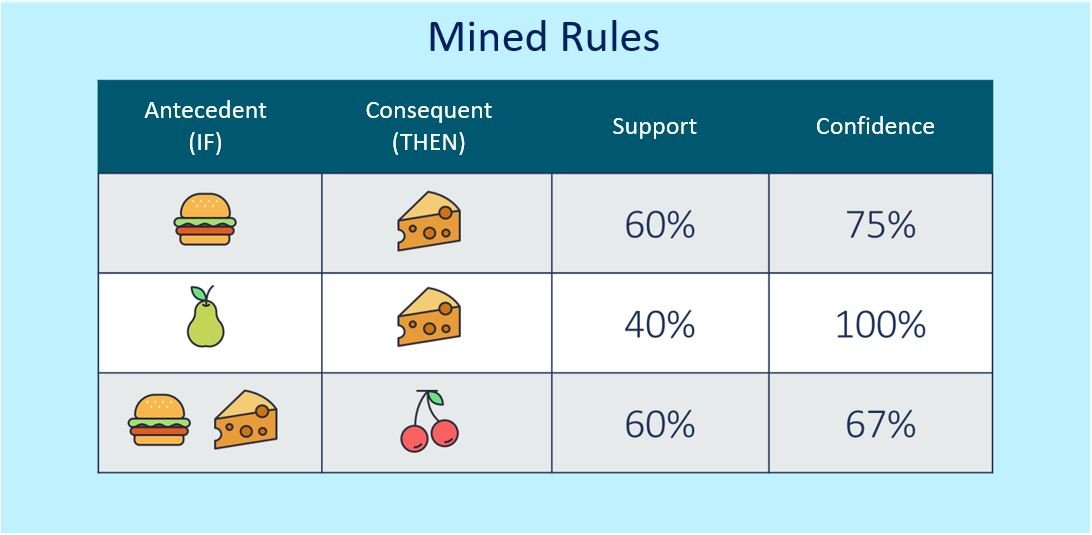
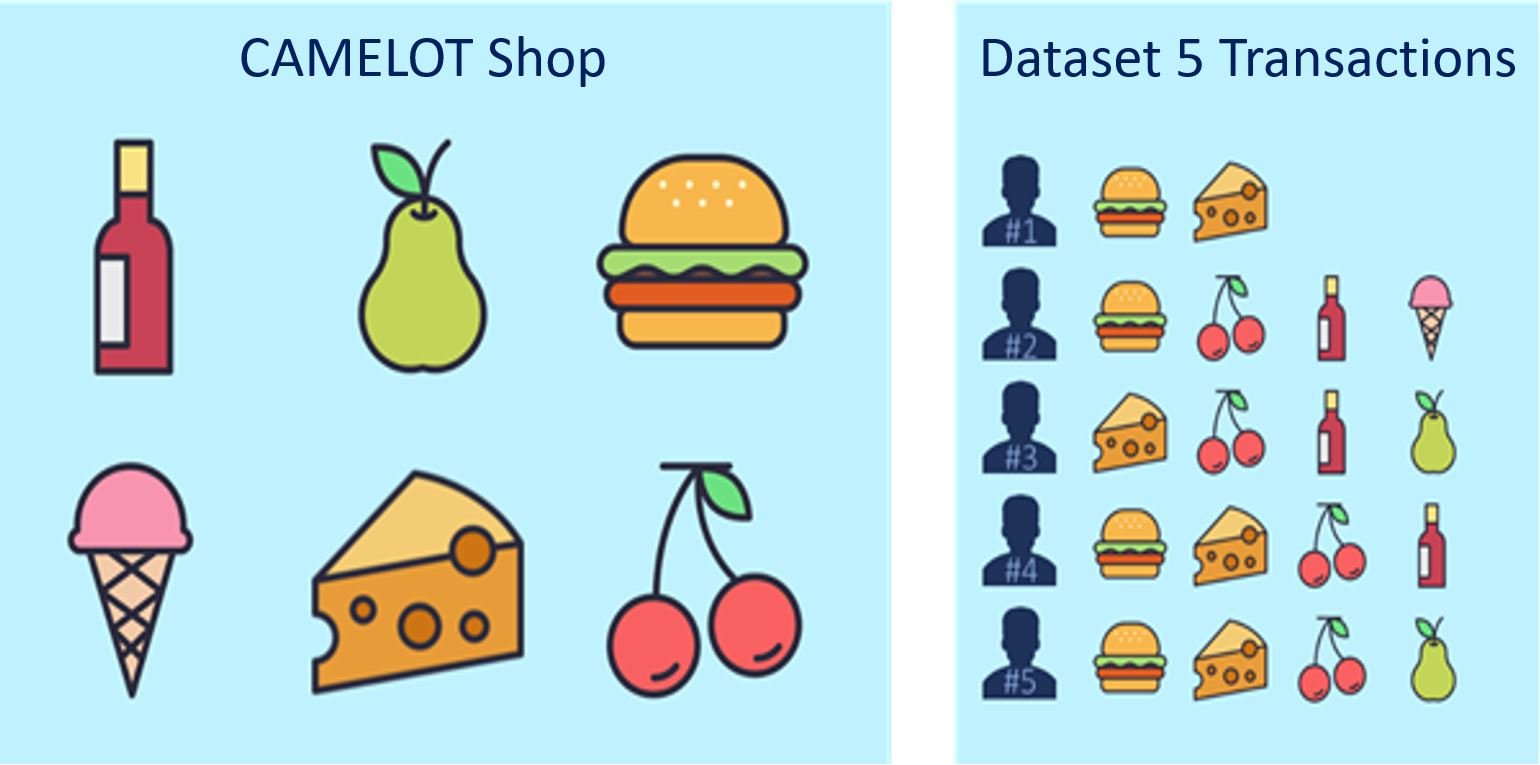
Figure 2 & 3: Market Basket Analysis Example with Mined RulesAs we observe in the table above, the first rule states that 75% of the customers who purchased a hamburger also bought cheese, with this relation occurring in 60% of the dataset. The second rule states that 100% of the customers who bought a pear also bought cheese, with the rule occurring as well in 40% of the data. Finally, the third rule is more complex, stating that 67% of the customers who bought a hamburger and cheese also bought cherries, while occurring in 60% of the data.
This simple example gives us an insight into the process of association rule mining. In practice, such algorithms are highly optimized and capable of computing large data sets for an immense number of rules in a few seconds. In practice, a small cluster of 10 computers can mine a million rules in less than a minute.
Rule Mining in Master Data Management
The rule mining algorithm can capture the patterns and relations of values among several attributes. The rules in that regard will hold the previously introduced structure:
IF column A has the value X then column B will have the value Y with a computed support and confidence values.
For example, we can derive a rule from master data, that if Industry Sector (MARA-MBRSH) is Pharmaceuticals (P) and Material Type (MARA-MTART) is a Finished Product (FERT) THEN Base Unit of Measurement (MARA-MEINS) is each.
The simple addition of the attribute-value pair rules opens new realm of possibilities and use cases.
Data Analytics and Insights
The algorithm that automatically derived all rules in a given dataset also provides the user with a detailed overview of the association rules within their data. Using a rule explorer, the user can interact with the extracted rules, filtering and examining interesting regions of the data. Thus, the user can identify resourceful patterns, and save those as rules, that can then be implemented in their master data services application or any other software that enforces rules for data entries.
Value Population Prediction
When creating new data entries, the derived set of rules could guide the user by suggesting most likely values. Instead of filling each value manually, the user will be prompted with a list of possible value entries and their computed probability from the mined data. With each new value inserted by the user, the algorithm will update its probabilities for the remaining empty fields.
Rule Compliance Checks
The set of rules mined in the process can later be used for compatibility checks. Each row in an unseen dataset can be investigated for rule adherence. Rows that do not comply with the rules are flagged for further investigation. The algorithm will highlight the non-compliant data, propose suitable alternatives to the user and enable corrections right within the application.
Additional use cases where rule mining can be utilized are for example during migration efforts or when combining several data sources. The algorithm will automatically detect deviations and violations of rules between sources.
The Fastest Way to Leverage Information Within Your Data
As shown before, rule mining in master data management serves several purposes. A dedicated solution like Intelligent Rule Mining quickly leads to a comprehensive overview of patterns and rules within your existing data. Compared to manually capturing rules, a rule mining approach also finds unexpected rules and identifies even more complex relationships. For a simpler workflow, business rules can be inserted directly into your master data management application and new data entries can be checked for compliance, improving data quality in the long run.
Intelligent Rule Mining is a solution of CAMELOT Intelligent Data Services (CIDS) and is successfully utilized by several of our customers.
To learn more about CAMELOT Intelligent Data Services visit the following link.
