
Im Dezember 2021 trafen sich Experten für Prognosen und Forecasting aus aller Welt auf der M5-Konferenz, um die Ergebnisse der jüngsten „M-Competition“ zu diskutieren, dem weltweit größten Wettbewerb im Bereich moderner Prognosen. Die Ergebnisse demonstrieren eindrucksvoll die Leistungsfähigkeit von Prognosemethoden, die Algorithmen des maschinellen Lernens (ML) nutzen und mehrere bewährte Konzepte kombinieren, um so die Prognosegenauigkeit erheblich zu erhöhen. In diesem Blogartikel werden Konzepte vorgestellt, als praktische Unterstützung für Experten, die vor der Optimierung ihrer Bedarfsprognosen und ihres Bedarfsplanungsprozesses stehen.
Was sind Prognosewettbewerbe?
Bedarfsprognosen dienen als Grundlage für die Supply Chain Planung. Für eine hervorragende Planung benötigen Unternehmen hochgenaue Bedarfsprognosen. Welche Bedeutung dieses Thema hat, zeigt sich auch in der großen Forschungsgemeinschaft, die ständig an neuen Konzepten arbeitet, die dazu beitragen, die Prognosegenauigkeit weiter zu erhöhen. Ein Hauptproblem aller neu entwickelten Methoden ist, dass sie nur eingeschränkt verallgemeinert werden können: Die Algorithmen funktionieren bei bestimmten (künstlichen) Daten gut, generieren aber keinen allgemeinen Wert. Um dieses Problem zu lösen, wurden Prognosewettbewerbe ins Leben gerufen. Die M-Competitions (benannt nach ihrem Veranstalter: Spyros Makridakis) sind die beliebtesten. Der letzte Wettbewerb, genannt M5, fand 2020 statt.
Prognosewettbewerbe: Warum sie für Experten relevant sind
Bei diesen Wettbewerben werden neue Prognosemethoden auf ihre Genauigkeit getestet. Sie konkurrieren dabei sowohl untereinander als auch mit etablierten Methoden. Die Tests basieren auf umfangreichen, realen Geschäftsdaten. So kann ihre Verallgemeinerung und Anwendbarkeit in der Praxis sichergestellt werden. Bei der M5-Competition ging es darum, die Verkaufsdaten von Walmart auf verschiedenen Aggregationsebenen zu prognostizieren. Das Ziel des Veranstalters war es, die Wettbewerbe so zu gestalten, dass sie für Wissenschaft und Praxis relevant sind.
In der Wissenschaft sind Prognosewettbewerbe als wichtige Innovationsquellen bekannt: An der M5-Competition nahmen über 5.000 Teams aus der ganzen Welt teil. Die Ergebnisse wurden und werden in wissenschaftlichen Arbeiten und Konferenzen breit diskutiert. Unter Praktikern der Branche finden sie jedoch nur wenig Beachtung: Haben Sie von ihnen gehört? Wenn nicht, teilen wir gern die wichtigsten Erkenntnisse, um sie Demand-Planern aus der Praxis zugänglich zu machen.
Die wichtigsten Erkenntnisse aus der M5-Competition
Aus praktischer Sicht lassen sich aus der M5-Competition fünf wesentliche Erkenntnisse ableiten. Die meisten beziehen sich auf neue algorithmische Konzepte zur Erhöhung der Prognosegenauigkeit. Es haben sich zwar alle Konzepte bewährt, sie unterscheiden sich jedoch in ihrer Komplexität und im Aufwand der Implementierung. Einige lassen sich leicht für jeden Komplexitätsgrad im Bedarfsplanungsprozess anpassen.
1. ML-Methoden besser als einfache Prognosealgorithmen
Alle Algorithmen, die bei der M5-Competition besonders gut abgeschnitten haben, nutzen Machine-Learning(ML)-Methoden. Hier werden leistungsstarke Algorithmen entwickelt, die aus historischen Daten lernen können. ML-Methoden sind sehr effektiv darin, Muster zu finden und diese Informationen zur Berechnung sehr genauer Prognosen zu verwenden.
Dass diese Methoden eine so viel bessere Leistung erbrachten, war etwas überraschend. Zuvor konnten komplexe Prognosemodelle einfachere Modelle (z.B. exponentielle Glättungsmodelle) jahrzehntelang nicht signifikant übertreffen. Aus diesem Grund waren und sind die einfacheren Methoden in der Praxis sehr beliebt, obwohl sie bereits in den 1950er Jahren entwickelt wurden. ML-Methoden haben sich in den letzten Jahren jedoch stark weiterentwickelt und sind heute präziser als einfachere Methoden. Insbesondere eine Kombination aus einfachen Methoden und ML-Fähigkeiten kann eine sehr hohe Prognosegenauigkeit erzielen. Dies ist nichts weniger als ein Paradigmenwechsel in der Bedarfsprognose.
2. Der Wert des Machine-Lernens über das gesamte Portfolio
Die genauesten ML-Methoden nutzen zusätzliche Informationen. Dazu gehören Daten, die im eigenen Produktportfolio stecken und durch sogenanntes Cross-Learning extrahiert werden können. Die Grundidee besteht darin, dem Prognoseverfahren zu ermöglichen, aus historischen Verkaufsdaten mehrerer verwandter Produkte oder Produktgruppen zu lernen. Es gibt verschiedene Möglichkeiten, diese Art von Informationen zu nutzen, wobei sich alle auf Cross-Learning beziehen:
Cross-Learning durch Aggregation beschreibt die Erstellung mehrerer Prognosen auf unterschiedlichen Aggregationsebenen, die für die endgültige Prognose kombiniert werden. Dadurch können Muster, die nur auf höheren Ebenen der Aggregation beobachtbar sind, auf niedrigere Produktebenen kaskadiert werden (siehe Abbildung 1).
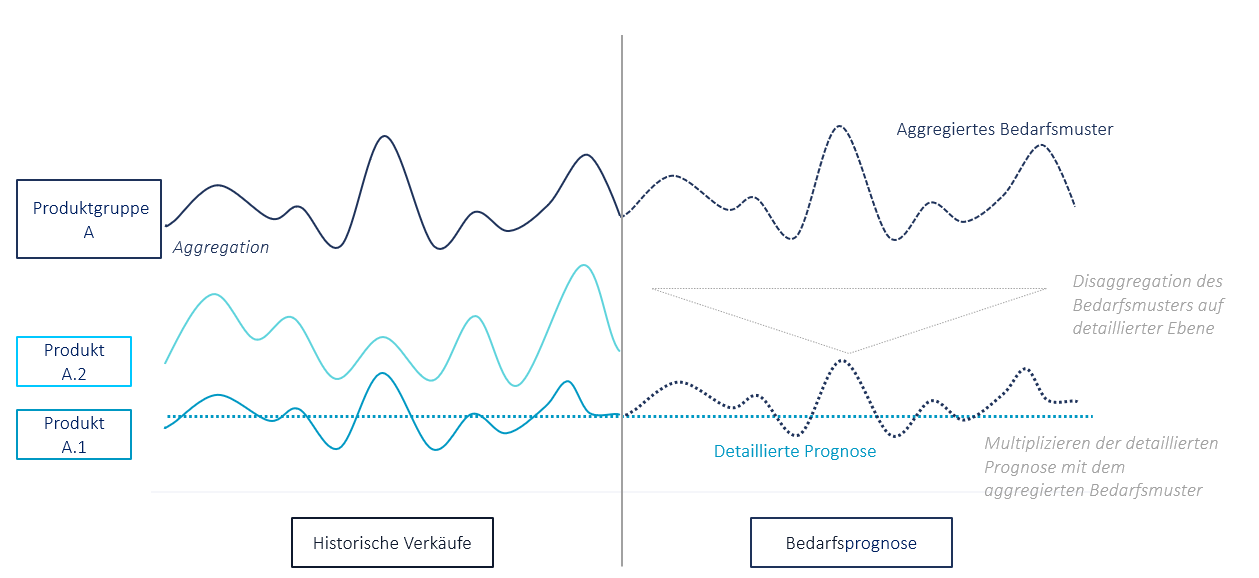 Abbildung 1: Cross-Learning durch Aggregation
Abbildung 1: Cross-Learning durch Aggregation
Cross-Learning durch Abhängigkeiten ist die Einbeziehung verwandter Zeitreihen als externe Eingaben, um die Muster einer einzelnen Zeitreihe zu erklären. Dadurch kann das Modell Produktabhängigkeiten wie Werbeeffekte nutzen (siehe Abbildung 2).
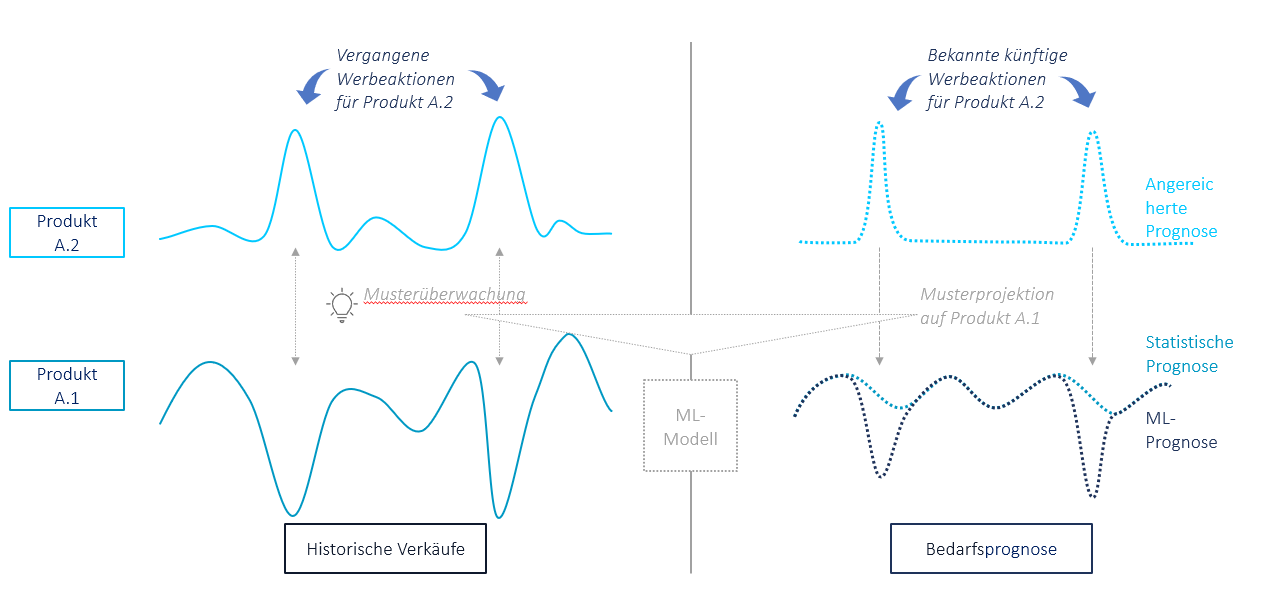 Abbildung 2: Cross-Learning durch Abhängigkeiten
Abbildung 2: Cross-Learning durch Abhängigkeiten
Globales Cross-Learning ist die Etablierung eines einzigen leistungsstarken Prognosemodells für alle Produkte. Dabei werden alle verfügbaren Informationen verwendet und das Modell kann aus verschiedenen Bedarfsmustern innerhalb des gesamten Datensatzes lernen (siehe Abbildung 3).
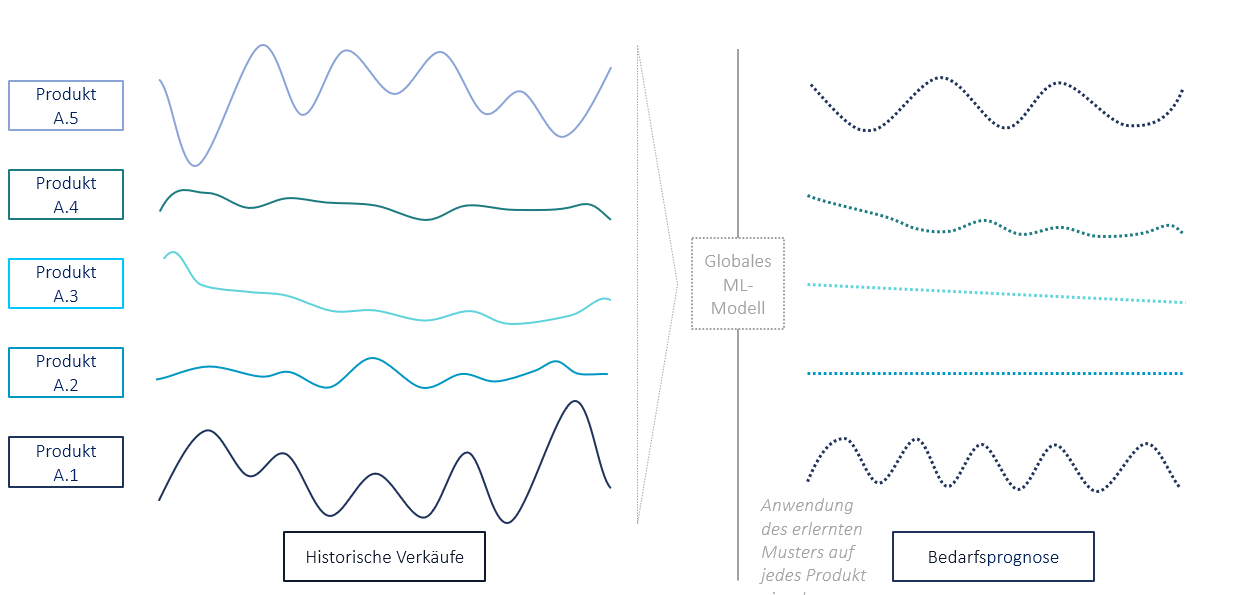 Abbildung 3: Globales Cross-Learning
Abbildung 3: Globales Cross-Learning
Cross-Learning kann die Prognosegenauigkeit stark erhöhen, wenn die richtigen Daten bereitgestellt werden können: hierarchisch strukturierte Bedarfsdaten mit Abhängigkeiten zwischen den Produkten.
3. Der Wert der Verwendung externer Daten
Eine weitere relevante Quelle für Prognosen sind alle Arten von externen Daten, die die Varianz in der Bedarfshistorie teilweise erklären können. Diese sogenannten erklärenden Variablen können Branchenindikatoren, Rohstoffpreise, interne Werbeaktionen usw. sein.
Für eine sinnvolle Verwendung dieser Daten in der Bedarfsprognose ist es erforderlich, dass die Variablen einen kausalen Einfluss auf die Nachfrage haben und nicht nur zufällig korrelieren. Gleichzeitig müssen sie für zukünftige Planungszeiträume zur Verfügung stehen. Wenn beide Bedingungen erfüllt sind, können sie in vielen ML-Methoden genutzt werden. Diese können nur die relevantesten erklärenden Variablen auswählen. Ergebnisse aus der Forschung weisen jedoch darauf hin, dass es sinnvoll ist, die Variablen, die dem Algorithmus bereitgestellt werden, vorab auszuwählen. Damit kann der Algorithmus die relevantesten Variablen aus einem bestimmten, vordefinierten Satz für jedes Produkt nutzen.
Es gibt keine allgemeine Regel, welche erklärenden Variablen verwendet werden sollten. Stattdessen ist die Entscheidung unternehmensabhängig und erfordert einen gewissen Einrichtungsaufwand. Danach kann der Prozess hochgradig automatisiert werden und der Wert dieser Variablen ist unumstritten.
4. Kombination von Prognosemethoden besser als Best-Fit-Ansätze
Die Genauigkeit der Prognose kann durch die Nutzung weiterer Informationen erhöht werden, und auch durch eine andere Art der Entscheidungsfindung in Bezug auf zu verwendende Methoden:
Seit Jahren gilt es als bewährtes Verfahren, hier einen Best-Fit-Ansatz zu nutzen. Dabei werden verschiedene Prognoseverfahren auf historischen Verkaufsdaten simuliert und das am besten passende Verfahren für Zukunftsprognosen verwendet. Dieses Verfahren hat jedoch mehrere Nachteile. Die Ergebnisse der M5-Competition zeigen, dass die Probleme der Verwendung nur eines Prognoseverfahrens durch die Kombination mehrerer Verfahren gelöst werden können (was die Ergebnisse der vorangegangenen M5-Competition bestätigt). Dies ist eine wichtige Erkenntnis, da Ansätze zur Kombination von Prognosemodellen einfach implementierbar sind. Weitere Informationen finden Sie im folgenden Blogartikel.
5. Die Notwendigkeit probabilistischer Prognosen
Bei der Zusammenfassung der Erkenntnisse aus der M5-Competition muss ein Thema erwähnt werden, das möglicherweise nicht direkt in die Praxis fließt: M5 war der erste Wettbewerb, bei dem der Ansatz, sich ausschließlich auf Punktprognosen zu konzentrieren (d.h. nur eine Zahl pro Zeitraum vorherzusagen), hinterfragt wurde. Zusätzlich zu den klassischen Werten zur Genauigkeit wurden alle Methoden auch anhand ihrer Leistung in Bezug auf die Unsicherheit ihrer prognostizierten Werte bewertet. Dies spiegelt das gestiegene Interesse an probabilistischen Prognosen wider, bei denen eine Verteilung von Prognosen für jeden Zeitraum berechnet wird – und nicht ein einzelner Wert, der am wahrscheinlichsten ist. Derzeit ist der Wert dieser Techniken in der Praxis jedoch begrenzt, da kein fortschrittliches Planungssystem in der Lage ist, Prognosen für Zeiträume (range forecasts) für nachfolgende Planungsprozesse zu verwenden.
Was bedeutet das für Experten in der Praxis?
Sie kennen jetzt die neuesten Trends für Bedarfsprognosen. Um die gewonnenen Erkenntnisse in die Praxis umzusetzen, sollten Sie zuerst den Reifegrad des Bedarfsplanungsprozesses Ihres Unternehmens ermitteln. Je nach Reifegrad können die vorgestellten Konzepte direkt übernommen werden oder sie fließen in eine längerfristige Vision, um Forecasting Excellence zu erreichen. Dabei gilt: Die Anwendung einfacher ML-Algorithmen (1), einfaches Cross-Learning (2), die Einbindung externer Datenquellen (3) und die Kombination mehrerer Prognoseverfahren (4) sind in standardmäßigen Planungssystemen realisierbar. Wenn Sie ausgefeiltere Konzepte umsetzen oder die Siegermodelle aus der M5-Competition direkt nutzen wollen, sollten Sie jedoch zusätzliche Data-Science-Funktionen verwenden. Für detailliertere Einblicke in dieses Thema lesen Sie unbedingt unseren folgenden Blog-Beitrag zu den Trends in der Bedarfsprognose.
Hier geht es zum zweiten Teil der Blog-Serie: Der schnellste Weg zur Steigerung der Prognosegenauigkeit
