In unseren früheren Posts zu Deep Learning „Eine kurze Geschichte der neuronalen Netze und „Warum neuronale Netze neuronal sind: das Perzeptron“ haben wir gezeigt, wie neuronale Netze entwickelt wurden, und erläutert, was genau es mit Perzeptren als Grundbaustein neuronaler Netze auf sich hat. In diesem Blogbeitrag möchten wir erklären, wie das Hinzufügen sogenannter „verborgener“ Schichten neuronale Netze in die Lage versetzt, komplexere Aufgaben zu lösen als ein Perzeptron, das nur eine Schicht besitzt.
Die versteckte Schicht
Wie in unseren vorherigen Blogbeiträgen gezeigt, liegt hinter neuronalen Netzen ein Modell, das in Schichten aufgebaut ist. Im letzten Blogbeitrag haben wir uns mit dem relativ einfach gebauten Perzeptron beschäftigt, das aus nur zwei Schichten besteht: einer Eingabeschicht und einer Ausgabeschicht. Wie gezeigt führt diese einfache Architektur dazu, dass das Perzeptron nur linear trennbare Klassifizierungsprobleme lösen kann, d. h. es kann Datenpunkte unterscheiden, die durch eine einzelne Gerade separiert werden können. In der Realität sind viele Klassifizierungsprobleme jedoch nicht-linear. Um dieser Tatsache Rechnung zu tragen, wurde der Gedanke des einschichtigen Perzeptrons erweitert: Es wurden weitere Zwischenschichten zwischen der Eingabe- und der Ausgabeschicht ergänzt. Diese Zwischenschichten werden als „versteckte“ Schichten bezeichnet, das erweiterte Netzwerk als „mehrschichtiges Perzeptron“.
Jeder Knoten einer versteckten Schicht führt mit den gewichteten Eingaben eine Berechnung durch, um einen Ausgabewert zu erhalten, der dann als Eingabe an die nächste Schicht weitergegeben wird. Diese nächste Schicht kann eine weitere versteckte Schicht oder die Ausgabeschicht sein, welche die Wahrscheinlichkeiten für die jeweilige Klassifizierung berechnet. Das Konzept der verborgenen Schicht gibt uns die Möglichkeit, komplexe mathematische Probleme zu lösen, etwa das sogenannte XOR-Problem.
Eine Lösung für das XOR-Problem
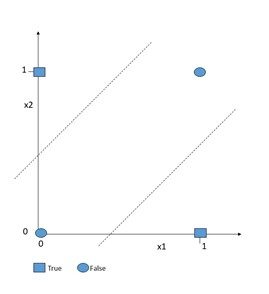
Abbildung 1: Das XOR-Problem
Das XOR-Problem ist die einfachste Beschreibung eines Problems, das ein Perzeptron nicht lösen kann. Da es nur zwei Eingaben gibt, ist beim XOR-Problem ein Neuron nur dann wahr, wenn die Eingaben der vorherigen Neuronen nicht identisch sind.
Für {(1,0), {0,1)} ist es also wahr, nicht aber für {(0,0), (1,1)}. Wenn wir dieses Problem im zweidimensionalen Raum darstellen (siehe Abbildung 1), so wird deutlich, dass es nicht durch ein einzelnes Perzeptron modelliert werden kann, da wir nicht in der Lage sind, wahre und falsche Datenpunkte durch eine einzelne Gerade zu trennen.
Das Einfügen einer weiteren versteckten Schicht zwischen der Eingabe- und der Ausgabeschicht löst das Problem jedoch. Wir führen eine einzelne versteckte Schicht ein, die aus zwei Neuronen besteht, die mit jedem Neuron der vorherigen Eingabe- und der nachfolgenden Ausgabeschicht verbunden sind, wie in Abbildung 2 dargestellt. Dabei ist zu bedenken, dass jedes Neuron ein Gewicht und einen Bias hat, die zufällig oder gemäß einer Wahrscheinlichkeitsverteilung initialisiert werden können. Die Ausgabe der versteckten Schichten H1 und H2 wird wie folgt berechnet:
- H1: σ (-x₁+x₂-0,5)
- H2: σ (x₁-x₂-0,5)
Zunächst wird die gewichtete Summe der Eingaben, die den Knoten erreichen, berechnet. Dann wird diese Summe als Eingabe für eine nicht-lineare Aktivierungsfunktion verwendet. Eine Aktivierungsfunktion definiert, wie die gewichtete Summe der Eingaben in eine Ausgabe umgewandelt wird. In diesem Fall wählen wir die Sigmoid-Funktion als Aktivierung sowohl auf der versteckten als auch auf der Ausgabeschicht. Die Sigmoid-Funktion ist eine S-förmige Kurve, die jeden Wert in einem Bereich zwischen 0 und 1 transformiert. Wenn das Ergebnis der Sigmoid-Funktion größer oder gleich 0,5 ist, klassifizieren wir diesen Knoten als Klasse 1 und lassen das Signal passieren. Wenn es kleiner als 0,5 ist, klassifizieren wir es als Klasse 0 und das Signal stoppt.
Die Funktion für den Ausgabeknoten lautet also wie folgt:
- σ (h₁+h₂-0,5)
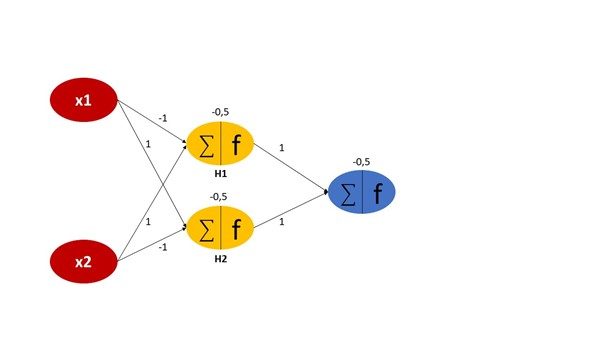
Wenn Sie dieses Netz mit den Kombinationen {(0,0), (0,1), (1,0), (1,1)} durchspielen, werden Sie sehen, dass die Ausgabe für (0,1) und (1,0) wahr und für (0,0) und (1,1) falsch ist. Mit anderen Worten: Das Netz löst das XOR-Problem. In diesem Beispielfall wurden die Gewichte und Biases so eingestellt, dass das Problem sofort gelöst wurde. Bei realen Problemen ist dies in der Regel nicht der Fall. Hier muss das Netz diese Parameter erst „lernen“, indem es wiederholt mit den Eingabedaten konfrontiert wird und die Gewichte so anpasst, dass es dem erwarteten Ergebnis näher kommt. Dieser Vorgang der Kalibrierung des Netzes wird Rückpropagieren (englisch: „backpropagation“) genannt.
Hierarchische Merkmale mit Deep Networks lernen
Im vorstehenden Abschnitt haben wir ein neuronales Netz mit einer einzigen versteckten Schicht beschrieben. Solche Netze werden als flache neuronale Netze bezeichnet. Dagegen wird jedes Netz, das mehr als eine versteckte Schicht umfasst, als tiefes Netz bezeichnet, woher auch der Begriff Deep Learning stammt. Forscher und Anwender im ML-Bereich arbeiten in der Regel mit tiefen Netzwerken, die aus Hunderten von Schichten bestehen können, vor allem, wenn die Datensätze sehr groß sind.
Was bringt es, wenn neuronale Netze immer tiefer werden? In tiefen Netzen findet während der Trainingsphase ein Vorgang statt, den man automatisches Feature-Learning nennt. Um Daten in verschiedene Kategorien unterteilen zu können, stützen sich Algorithmen für maschinelles Lernen auf Merkmale, die in den Daten enthalten und in verschiedenen Kategorien unterschiedlich sind. Ein Bildklassifizierer, der Bildmotive in Hunde und Katzen einteilt, könnte hierzu zum Beispiel die Gesamtgröße des Tieres oder die Größe und Form der Nase und andere Gesichtsmerkmale heranziehen.
Bei traditionellen Algorithmen für maschinelles Lernen muss der Data Scientist diese Merkmale explizit als Bestandteil der Trainingsdaten zusammen mit den Klassifizierungsinformationen bereitstellen. Der Algorithmus kann dann in der Trainingsphase Interaktionen zwischen den Merkmalen und den Zielkategorien lernen. Deep Learning-Modelle hingegen benötigen keine expliziten Merkmalsinformationen, sondern lernen Merkmale von selbst, ohne dass der Mensch eingreifen muss. Dies spart viel Zeit, die andernfalls für die manuelle Erstellung zusätzlicher Features/Attribute aufgewendet werden müsste. Tiefe Netzwerke verdanken ihre Fähigkeit zum automatischen Lernen von Merkmalen ihrer geschichteten Topologie. Yoshua Bengio, ein Pionier der Deep-Learning-Forschung, erklärt es in seinem Artikel „Learning Deep Architectures for AI“ (2009, pdf) wie folgt:
“Deep learning methods aim at learning feature hierarchies with features from higher levels of the hierarchy formed by the composition of lower-level features. Automatically learning features at multiple levels of abstraction allow a system to learn complex functions mapping the input to the output directly from data, without depending completely on human-crafted features.”
Quelle: Yoshua Bengio, Learning Deep Architectures for AI, 2009, pdf
Für unseren Bildklassifizierer würde das vereinfacht Folgendes bedeuten:
- Zunächst lernt der Algorithmus, die im Bild auftretenden Kanten zu erkennen.
- Dann folgen Grundformen und Konturen.
- Dann lernt er, Augen, Ohren und andere Gesichtszüge zu erkennen,
- gefolgt von der Erkennung ganzer Gesichter.
- Und schließlich kann er durch die Kombination des Gesichts mit möglicheren anderen Merkmalen zwischen den sehr abstrakten Konzepten von Hunden und Katzen unterscheiden.
In einem Deep-Learning-Netz erlernt jede Knotenschicht auf der Grundlage der Ausgabe der vorherigen Schicht einen bestimmten Satz von Merkmalen. Je mehr Schichten das Netz hat, desto spezifischer sind die Merkmale, die die Knoten erkennen können, da sie die in den vorherigen Schichten gelernten Merkmale zusammenfassen.
Wie viele versteckte Schichten sind sinnvoll?
Nachdem wir nun geklärt haben, wozu versteckte Schichten dienen, bleibt eine Frage offen: Wie viele Schichten braucht ein neuronales Netz eigentlich? (siehe diese Diskussion auf stackexchange)
Die Anzahl der Schichten und die Anzahl der Knoten in jeder versteckten Schicht sind für die Architektur und Topologie des Netzes die beiden wichtigsten Parameter. Wenn ein Netz nun durch das Hinzufügen weiterer Schichten immer abstraktere Merkmale erlernen kann, wäre es dann nicht sinnvoll, die Anzahl der Schichten so lange zu erhöhen, bis sich keine signifikante Reduzierung des Trainingsfehlers mehr feststellen lässt? Theoretisch schon, allerdings gibt es hier zwei wichtige Punkte zu bedenken: Erstens steigt mit der Anzahl der Schichten der Rechenaufwand, da das Modell mehr Parameter lernen muss. Und zweitens steigt mit zunehmender Tiefe des neuronalen Netzes die Gefahr des Overfittings, der Überanpassung. Ein Overfitting liegt vor, wenn ein Modell bei den vorliegenden Trainingsdaten sehr gut abschneidet, seine Leistung jedoch bei ungesehenen Daten nachlässt.
Dieser Effekt tritt auf, wenn die Gewichte so angepasst werden, dass das System sich an die Trainingsdaten „erinnert“, aber nicht die zugrundeliegenden Merkmalsinteraktionen lernt, die in den Daten enthalten sind. Die Antwort ist also die Gleiche wie beim traditionellen maschinellen Lernen: Die Anzahl der Schichten und die Anzahl der Knoten in jeder versteckten Schicht sind Parameter, die auf der Grundlage vieler Experimente und der Messung des Testfehlers bestimmt werden müssen.
Nachteile des Deep Learning
Nun fragen Sie sich vielleicht, warum neuronale Netzwerke nicht für jedes Problem des maschinellen Lernens verwendet werden, wenn sie doch so leistungsfähig sind. Das liegt daran, dass sie einige Unzulänglichkeiten aufweisen. Deswegen möchten wir im folgenden letzten Abschnitt die beiden wichtigsten Nachteile betrachten:
Ressourcenverbrauch
Neuronale Netze verbrauchen Unmengen an Ressourcen. Je umfangreicher sie werden, desto komplexer sind sie, und desto mehr Daten und Rechenleistung werden benötigt, um sie effektiv zu trainieren.
Es gibt zum Beispiel einen berühmten Datensatz für die Klassifizierung handgeschriebener Zahlen namens „MNIST“, der aus über 60.000 Bildern handgeschriebener Ziffern von 0 bis 9 besteht. Flache neuronale Netze können dieses Problem in einer angemessenen Zeit erlernen und lösen, aber verglichen mit der Art und Weise, wie Kinder dieselben zehn Ziffern lernen, sind die Kinder deutlich effizienter – sie müssten sich nicht erst 60.000 Bilder anschauen. Neuronale Netze sind sehr datenhungrig, und je tiefer sie werden, desto mehr Daten muss man einspeisen.
Mangelnde Nachvollziehbarkeit
Ein weiteres Problem ist die mangelnde Nachvollziehbarkeit: Da tiefe neuronale Netze aus Tausenden oder sogar Hunderttausenden von Neuronen bestehen, ist es schwierig, das eine oder die wenigen Neuronen zu identifizieren, die für eine Entscheidung ausschlaggebend waren. Der Blackbox-Charakter neuronaler Netze macht ihre Vorhersagen kaum erklärbar. Gerade für Unternehmensanwendungen kann es jedoch von großer Bedeutung oder aus Compliance-Gründen sogar zwingend erforderlich sein zu erklären, warum bestimmte Entscheidungen getroffen wurden. Es muss zum Beispiel erklärbar sein, warum ein neuronales Netz einen potenziellen Darlehensnehmer bei einer Bonitätsprüfung als „kreditwürdig“ oder als „nicht kreditwürdig“ einstuft. In solchen Fällen ist es besser, auf Algorithmen für maschinelles Lernen zurückzugreifen, bei denen man leichter nachvollziehen kann, wie die Vorhersage zustande gekommen ist. Ein Beispiel hierfür sind auf Entscheidungsbäumen basierende Ensemble-Algorithmen.
Weitere Artikel zu verwandten Themen für Data-Driven Leaders finden Sie hier.
Wir danken Stefan Morgenweck und Tobias Walter für ihren wertvollen Beitrag zu diesem Artikel.
