
Datenregeln beschreiben Geschäftsvorgänge, Definitionen und Einschränkungen für die Daten eines Unternehmens. Diese spiegeln die Geschäftsstruktur wider, leiten oder steuern das Unternehmensverhalten und werden eingerichtet, um das Unternehmen beim Erreichen seiner Ziele zu unterstützen. Camelots intelligente Rule Mining-Lösung auf Basis von SAP Data Intelligence bietet ein flexibles und vielseitiges Toolset, um Datenabhängigkeiten zu identifizieren und die allgemeine Datenqualität Ihres Unternehmens zu verbessern.
Automatisierte Extraktion der Geschäftslogik und Datenpopulation mit einer intuitiven Benutzeroberfläche
Datenregeln variieren in ihrer Komplexität. Datenrichtlinien, z. B. die Anforderung der Zeichen „.“ und „@“ für gültige E-Mail-Adressen können als nicht komplexe Regeln eingestuft werden und sind leicht auf Feldebene festzulegen. Allerdings können aus Daten noch mehr Werte gewonnen werden. Basierend auf der Semantik Ihrer Daten können komplexe Regeln auch in Form von Wenn-Dann-Abhängigkeiten abgeleitet werden, z. B. was sind bei gegebenen Wert A eines Feldes die wahrscheinlichsten Implikationen für die Werte der anderen Felder? Im Vergleich zu nicht komplexen Datenrichtlinien erfordern diese Abhängigkeiten einen anfänglichen Analyseschritt und sind daher komplexer in der Auffindung und Nutzung. Insbesondere die Extraktion komplexer Abhängigkeiten ist ein aufwendiger Prozess für Domainexperten, da es schwer ist, deren Anwendbarkeit über verschiedene Systeme zu überprüfen. Darüber hinaus ist die Identifizierung fehlerhafter Dateneinträge eine komplexe und zeitaufwändige Aufgabe, die von Datenarchitekten oder Data Owner in Unternehmen manuell durchgeführt werden muss.
Camelots intelligente Rule Mining-Lösung auf Basis von SAP Data Intelligence bietet ein flexibles und vielseitiges Toolset, um Datenabhängigkeiten zu identifizieren und die allgemeine Datenqualität Ihres Unternehmens zu verbessern – innerhalb oder über Ihre Stammdaten hinaus. Setzen Sie qualifizierte Ressourcen frei, indem Sie den Zeitaufwand für langwierige Data-Mining-Aufgaben reduzieren und auf der Grundlage Ihrer Daten szenariospezifische Regeln einfach identifizieren.
Datenabhängigkeiten identifizieren
Mit dem leistungsstarken Verbindungsmanagement von SAP Data Intelligence können Sie eine direkte Verbindung zu Ihrern HANA-Datenbanken herstellen und auf Ihre Datenlandschaft zugreifen. Von dort aus können Sie verfügbare Tabellen und Spalten auswählen, um ein Szenario zum Rule Mining zu erstellen. Sie haben auch die Möglichkeit, Ihre Datentabellen im CSV-Format in die Rule Mining-Lösung hochzuladen. Durch das Mining der hochgeladenen Daten werden automatisiert Abhängigkeiten zwischen scheinbar unabhängigen Daten auf Grundlage der gewählten Datenquellen extrahiert und identifiziert, z. B. Produktentwicklungsstatus oder Gefahrstoffe.
Datenregeln in Regelsätzen verwalten
Auf Basis der analysierten Daten können Regeln identifiziert und in Bezug auf ihre Relevanz eingestuft werden. Nutzer haben die Möglichkeit „goldene“ Regelsätze für ihr Unternehmen zu definieren, diese im Repository zu speichern und in Excel zu exportieren. Dies beinhaltet auch die Option, Regelsätze mit neuen Datenquellen zu vergleichen und Datenqualitätsberichte zu erstellen, z. B. einen Vergleich von Stammdatenregeln mit Supply-Chain-Daten.
Wertvorhersagen für Unternehmensanwendungen
Wenn diese Datenregeln eingerichtet sind, können Datenausreißer und Nichteinhaltung von Regeln schnell durch Validierung der Regelkonformität und erwartete Werte für jede andere Datenquelle in Ihrem Unternehmen entdeckt werden. Wenn die Daten nicht schlüssig sind, werden betroffene Zeilen in Ihrem Datensatz hervorgehoben und korrekte Werte können automatisch eingefügt werden. Darüber hinaus ermöglicht die Lösung neben der Regelverwaltung in unserer intuitiven Benutzeroberfläche auch programmatische Aufrufe des analysierten Wissens mit Hilfe einer offenen API: Geben Sie einfach eine Kombination von Feldern mit einigen der entsprechenden Werte ein und die Antwort enthält die wahrscheinlichsten Werte für die leeren Felder.
Vorteile
Identifizieren und vergleichen Sie komplexe Unternehmensregelsätze mit weiteren Datenquellen innerhalb Ihres Unternehmens. Die Lösung identifiziert Dateninkonsistenz durch Ausreißererkennung, Konfidenz- und Häufigkeitsanalyse bei der Datenverteilung und unterstützt den Nutzer bei der Eingabe von Feldwerten durch Eingabevorschläge und automatisierte Datenpopulationsoptionen. Dies führt zu einer insgesamt höheren Datenqualität, was die Entscheidungsfindung in Ihrem Unternehmen stärkt und die Effizienz steigert.
Technische Informationen
SAP Data Intelligence ermöglicht eine vielseitige Datenmanipulation in der Unternehmenslandschaft durch den Einsatz von gekapselter Logik der Operatoren in den Datenpipelines. Dieses Paradigma bietet maximale Wiederverwendbarkeit des Codes, eine einfache Schnittstelle zur Abstimmung der Einstellungen und die Flexibilität, unterschiedlichen Systemanforderungen gerecht zu werden. Nach diesem Prinzip bieten wir einen Rule Mining-Operator an, der die zu untersuchenden Daten und Spalten als Input nimmt und die Ergebnisse als Output zur Speicherung in der Wissensdatenbank ausgibt. Sobald die Daten gespeichert sind, wird ein offener API-Operator verwendet, um dem Nutzer verschiedene Funktionalitäten auf Basis des generierten Wissens offen zulegen (z. B. Regeln, Zusammenfassung und Filtern, Ausfüllen von Feldwerten, nicht konforme Reihen, usw.). Der Prozess ist im folgenden Diagramm beschrieben:
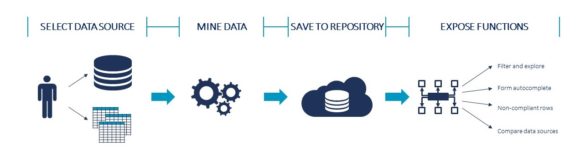
Der Operator für das Rule Minung verwendet eine Implementierung des Parallel Frequent Pattern Tree Growth Algorithmus. Der Operator nutzt ein lokales Spark-Cluster, um verteilte Rechenkapazitäten für das Rule Mining zu ermöglichen, was zu einer schnelleren Verarbeitungszeit führt. Bei SAP Data Intelligence haben Sie außerdem die Option, in der Pipeline je nach Datenkomplexität extra CPU und Speicher zuzuweisen.
Neue Datenquellen können einfach aufgenommen und derselben Pipeline zugeordnet werden, indem alle vorgefertigten SAP-Operatoren genutzt werden. Daten können aus verschiedenen Clouds oder On-Premise Datenbanken (MSSQL, MySQL…) bereitgestellt werden. Darüber hinaus können Datenaufträge über SAP Data Service gestartet und SAP Business Warehouse Data Marts genutzt werden. Auf die gleiche Weise kann das gewonnene Wissen in jedes nachgelagerte System weitergegeben werden.
Interesse geweckt?
Sie möchten mehr über die Data-Intelligence-Lösungen von Camelot erfahren? Lesen Sie die folgenden Informationen oder besuchen Sie uns auf unserer Webseite:
- Kunden-Anwendungsfall Evonik
- EXTREME DATENAUTOMATISIERUNGSLÖSUNG
Interessiert? Sprechen Sie uns gerne direkt an über dataintelligence@camelot-group.com.
