
Potenziale der saisonalen Prognose mit KI stärken
Der erste Einsatz der Lösung reduzierte den Sicherheitsbestand für 10 saisonale Produkte um 2.000 Tonnen, was eine Kostensenkung um 950.000 € pro Jahr bewirkte.
Budgetplanung und Bedarfsprognose sind die wichtigsten Steuerungsinstrumente innerhalb der Lieferkettenplanung. Dennoch ist es eine ständige Herausforderung, den zukünftigen Bedarf richtig vorherzusagen. Ein Komplexitätstreiber ist der enorme Umfang der Portfolioprognosen, die jeden Monat generiert werden müssen. Die meisten Unternehmen haben mit 1 bis 15 Millionen Prognosen für jede Produkt-, Länder- und Kundenkombination zu kämpfen. Ein genauer und belastbarer Prognosealgorithmus ist unerlässlich, um dieser Herausforderung zu begegnen. Insbesondere die Saisonalität ist ein wesentlicher Volatilitätstreiber und damit ein Hauptfaktor für die Lieferkettenkosten.
Es hat sich gezeigt, dass der Einsatz neuronaler Netze der traditionellen Heuristik bei der Erkennung saisonaler Muster überlegen ist. Dagegen übertreffen herkömmliche Prognosealgorithmen neuronale Netze bei der Prognosegenauigkeit, wenn nur die Auftragshistorie für die Modellierung verwendet wird. Heute ist die Kombination von neuronalen Netzen mit herkömmlichen Prognoseverfahren der Schlüssel für die erfolgreiche Bewältigung der Herausforderungen bei der Bedarfsprognose.
Der richtige Prozess
Wir bewältigen die Herausforderung, die Bedarfsprognose zu steuern, indem wir KI und herkömmliche Methoden in Bezug auf statistische Daten optimal kombinieren. Es zeigt sich, dass das folgende Prognoseverfahren empfehlenswert ist:
- Einsatz neuronaler Netze für die Klassifizierung von Zeitreihen früherer Aufträge, um saisonale Produkte zu identifizieren.
- Zuordnung geeigneter Prognosemodelle zu saisonalen Produkten (z. B. saisonale Regression, exponentielle Glättung).
- Erstellung einer Ex-post-Prognose, um die Prognosegenauigkeit für saisonale Produkte zu ermitteln.
- Überprüfung und Anpassung von Modellen und Parametrierung für Produkte mit hohem Fehlerrisiko und hoher Nachfrage.
- Segmentierung von Produkten nach Wichtigkeit und Prognosegenauigkeit.
- Ableitung einer optimalen Lieferkette und Systemkonfiguration für jedes Segment.
Was wir bislang veröffentlicht haben: selbstlernende Erkennung von Bedarfsmustern
Wir haben ein neuronales Netzwerk (CNN) mit einem Datensatz trainiert, der etwa 60.000 bereits korrekt klassifizierte Zeitreihen mit 36 Bedarfsperioden enthält (siehe Abbildung 1 links). Die Aufgabe für das neuronale Netz besteht darin, die Zeitreihen korrekt in die sechs verschiedenen Muster einzuordnen. Wir haben das neuronale Netz mit 32.000 Zeitreihen trainiert. 8.000 wurden für die Validierung während des Trainings verwendet. Nach der Trainingsphase setzten wir das neuronale Netzwerk zur Klassifizierung von 20.000 Zeitreihen ein, die dem Netz zu diesem Zeitpunkt völlig unbekannt waren.
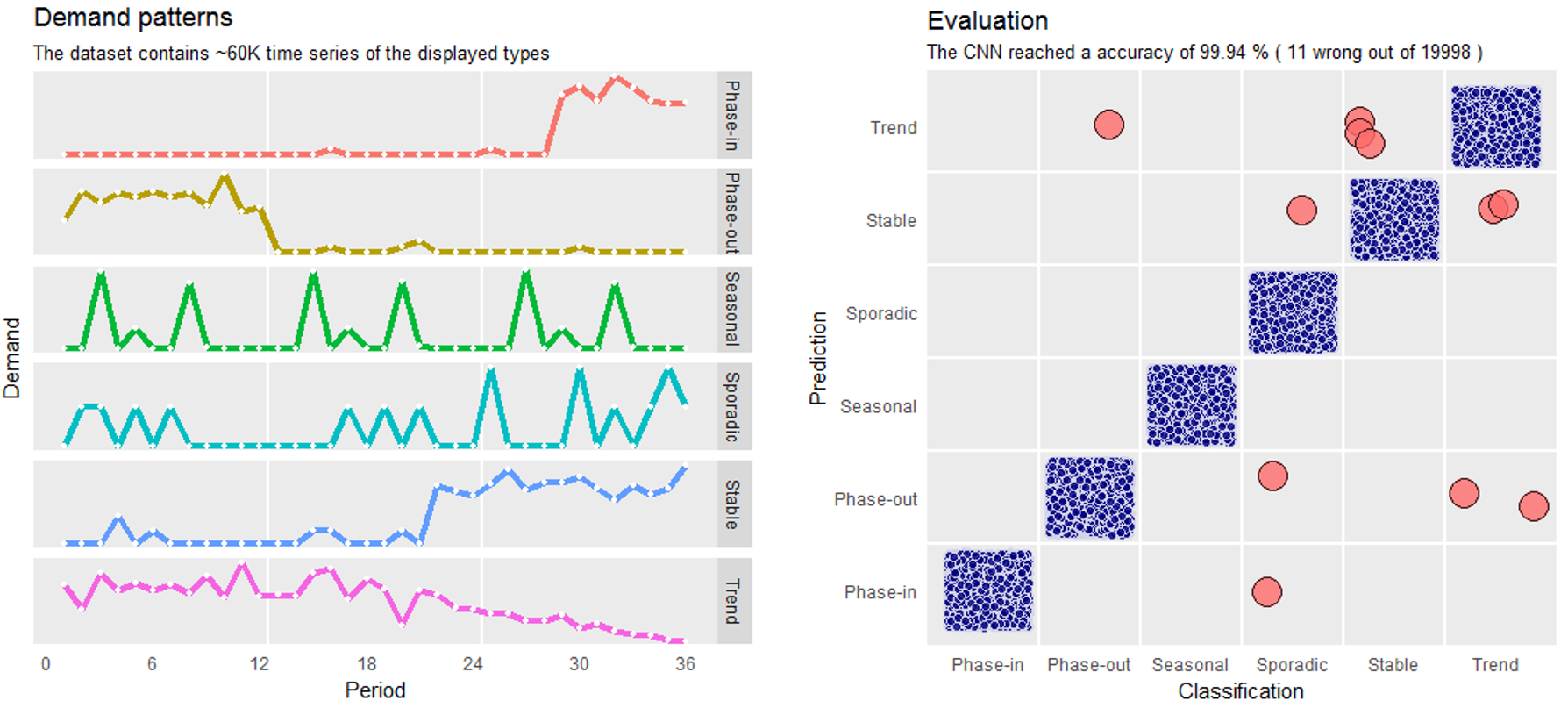
Abb.1: Test und Auswertung der Bedarfsmustererkennung
Beim Test-Datensatz hat das CNN eine Genauigkeit von 99,94 Prozent erreicht. 11 Bedarfsmuster aus 20.000 Zeitreihen wurden falsch klassifiziert (siehe Abbildung 1 rechts). Die Berechnung für die Klassifizierung dauert 0,43 Sekunden, was 0,0000215 Sekunden pro Zeitreihe entspricht. Im Vergleich zu Mensch oder Statistik ist das neuronale Netz überlegen – sowohl in Bezug auf die Berechnungszeit als auch bei der Genauigkeit.
Beispiel: Prognose des saisonalen Bedarfs
Wir verwenden ein Produktportfolio, das aus 5.000 Produkten besteht. Wir stellen für jedes Produkt eine Bedarfshistorie von 40 Monaten bereit und nutzen ein Jahr, um unsere Ex-post-Prognose zu testen. Darüber hinaus vergleichen wir drei Prognosemodelle mit der Methode der expandierenden Fensterbreite: Als Referenzmodell werden ein Modell der exponentiellen Glättung erster Ordnung (additiv mit Alpha = 0,3), ein Modell der exponentiellen Glättung dritter Ordnung (additiv mit Alpha = 0,3 und Gamma = 0,3) ohne Trendkomponente und ein CNN-basiertes Prognosemodell verwendet, das mit 5.000 Beobachtungen über den Trainingshorizont trainiert wurde. Jedes Modell folgt dem Prinzip der rollierenden Prognose. Sie werden anhand des durchgangsabhängigen Trainingshorizonts trainiert und anhand der nächsten 12 Monate getestet. Die Verzögerung in jedem Evaluierungsszenario entspricht einem Monat (siehe Abbildung 2).

Abb.2: Die Prognostizierten Werte aller Modelle
Tabelle 1 fasst die Querauswertung der Modelle zusammen. In allen Durchgängen ist das Modell der exponentiellen Glättung dritter Ordnung in Bezug auf die MSE- und WMAPE-Werte überlegen, gefolgt vom Modell des neuronalen Netzes. Beide Modelle erzeugen einen geringeren MSE- und WMAPE-Wert als das Referenzmodell der exponentiellen Glättung erster Ordnung. Somit übertrifft die exponentielle Glättung dritter Ordnung das KNN bei der saisonalen Prognose in Bezug auf die Genauigkeit.
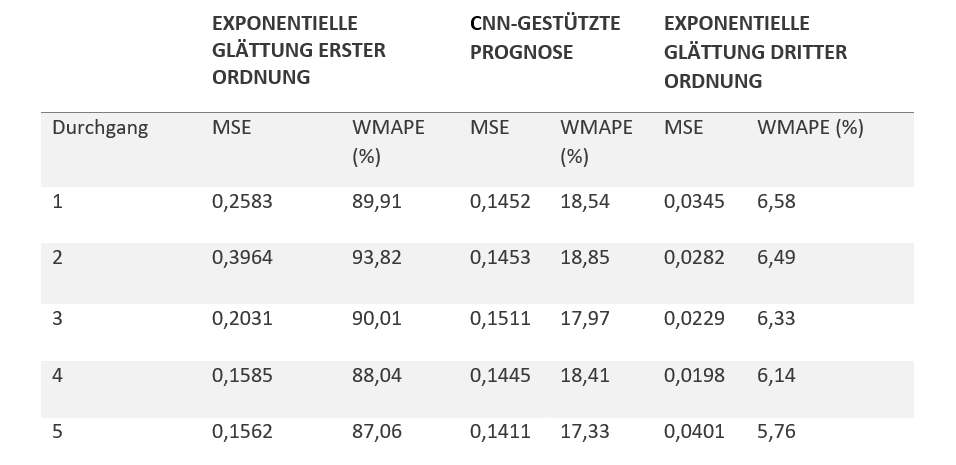
Tabelle 1: Zusammenfassende Quervalidierung mit der Methode expandierender Fensterbreite
Nutzenargument: Senkung der Kosten für den Pufferbestand für saisonale Produkte
Das vorgeschlagene Prognosekonzept haben wir in einem Projekt in der Chemiebranche angewendet. Das Portfolio besteht aus 5.200 Produkten mit der Bedarfshistorie von drei ganzen Jahren. Zuerst haben wir das neuronale Netzwerk zur Klassifizierung von Bedarfsmustern eingesetzt. Es erkannte 10 saisonale Produkte mit einem Gesamtauftragsvolumen von 17.630 Tonnen im letzten Jahr. In der Vergangenheit wurde diese Aufgabe manuell ausgeführt: Saisonale Produkte wurden übersehen oder sogar falsch erkannt. Als Zweites haben wir das Modell der exponentiellen Glättung dritter Ordnung verwendet, um für jedes Produkt eine Prognose zu erstellen, und es mit der Prognose des Kunden verglichen. Als Ergebnis der neuen Verteilung durch dieses Prognosemodell lässt sich eine Erhöhung der Prognosegenauigkeit um 20,06 Prozent festhalten. Dies bewirkt eine Reduzierung des Sicherheitsbestands um 2.000 Tonnen und damit eine Kostensenkung um 950.000 € pro Jahr.
Weniger „Roboter“ im Menschen
Ein Aspekt der Digitalisierung ist die Reduzierung fehleranfälliger manueller Tätigkeiten: Tagelange monotone Arbeit zur Erledigung von sich monatlich, wöchentlich oder sogar täglich wiederholenden Aufgaben verringert die Leistungsfähigkeit von Menschen und „reibt die Mitarbeiter auf“. Derartige Tätigkeiten gibt es in vielen Unternehmensbereichen, wie etwa bei der Bedarfsplanung. Ein geschickter Mix aus KI und herkömmlichen Methoden unterstützt den Planer dabei, Bedarfsmuster zu finden und zukünftigen Bedarf zu prognostizieren, und hilft bei der gezielten Priorisierung von wichtigen Planungsentscheidungen. Damit ist die Parametrierung nahezu vollständig automatisiert und der manuelle Planungsaufwand auf ein Minimum reduziert. Wir verbinden innovative und operative Prozesse, um die tiefen datengestützten Einsichten in die täglichen Entscheidungen einzubeziehen. Das ist es, was die Digitalisierungsstrategie von Camelot ausmacht: Den „Roboter“ aus dem Menschen holen.
Wir bedanken uns bei Torben Hügens für seine Mitbarbeit an diesem Artikel.
