Eine der großen Herausforderungen, denen sich Data Scientists zu stellen haben, ist die Frage, wie man mit Hilfe von Daten bestimmte Probleme lösen kann. Immer wieder treten die unterschiedlichsten Unternehmen an sie heran, die ihre Probleme mit Hilfe von maschinellem Lernen und KI gelöst sehen wollen. Dabei handelt es sich bei vielen dieser Aufgabenstellungen gar nicht um datenwissenschaftliche Probleme. Wenn also ein Unternehmen einen Data Scientist bittet, eine Datensammlung zu untersuchen, muss er sich zunächst fragen, ob das Problem durch Datenanalyse lösbar ist oder nicht. Und falls das der Fall ist, wie die Sache am besten anzugehen ist.
Die explorative Datenanalyse
Die explorative Datenanalyse (EDA) ist ein Ansatz, mit dem Informationen aus einer Datensammlung gewonnen und die Hauptcharakteristika dieser Daten zusammengefasst werden. Sie gilt als entscheidender Schritt in jedem Data-Science-Projekt (in Abbildung 1 ist sie als zweiter Schritt nach der Problemanalyse im CRISP-Datenmodell dargestellt). Viele unterschätzen die Bedeutung der Datenvorbereitung und -exploration. Die EDA ist essenziell für ein klar definiertes und strukturiertes Data-Science-Projekt und sollte noch vor statistischen oder ML-Modellphasen erfolgen. In diesem Blogpost konzentrieren wir uns darauf, wie eine EDA abläuft und welche Technologien wir bei Camelot für die Datenanalyse und -visualisierung verwenden. 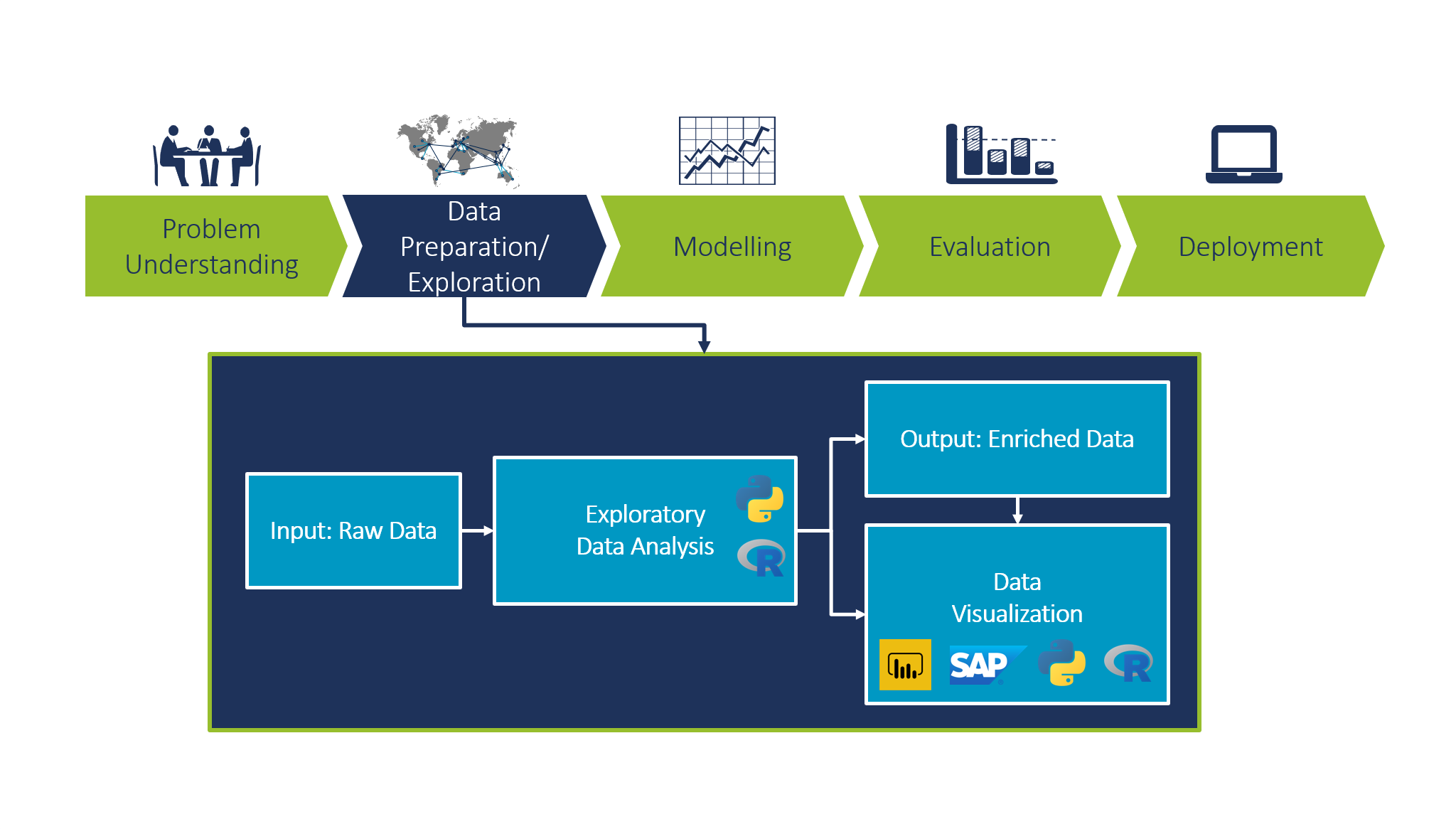 Abb. 1: Ablauf eines Data-Science-Projekts
Abb. 1: Ablauf eines Data-Science-Projekts
Datenvorbereitung
Die Datenvorbereitung umfasst die Bereinigung und Organisation der realen Daten und nimmt bekanntermaßen mehr als 80% der Arbeitszeit eines Datenwissenschaftlers in Anspruch. Reale Daten oder Rohdaten sind unsortiert, es fehlen Werte, dafür sind zahlreiche Duplikate und in manchen Fällen auch falsche Informationen enthalten. Die meisten Algorithmen des maschinellen Lernens können mit fehlenden Werten nicht umgehen, daher müssen die Daten zunächst konvertiert und bereinigt werden. Übliche Lösungen für die Bereinigung fehlender Werte sind das Löschen von Zeilen, lineare Interpolation, die Verwendung von Mittelwerten usw. Je nach inhaltlicher Bedeutung und Anzahl der fehlenden Werte kann eine dieser Lösungen angewendet werden. Wir von Camelot nutzen für die Datenvorbereitung und -vorbearbeitung hauptsächlich Python und R (Programmiersprachen, die von Data Scientists häufig in ihrer täglichen Arbeit verwendet werden).
Datenexploration
Sobald ein bereinigter Datensatz vorliegt, müssen wir die Daten analysieren, ihre Eigenschaften zusammenfassen und sie visualisieren. Die Analyse der Daten ist ein schrittweiser Prozess, der zwischen dem Data-Science-Team und den Experten der Unternehmensseite stattfindet. Sie kann beiden Seiten helfen, die wichtigsten Merkmale zu identifizieren und aufzubauen, um dann geeignete Machine-Learning-Modelle zu entwickeln. Ein wesentlicher Teil der Datenexploration ist die Datenumwandlung. Dazu ein Beispiel: Stellen wir uns ein Prognoseproblem im Logistikbereich für eine bestimmte Anzahl von Lieferungen an verschiedene Orte durch unterschiedliche Lieferanten vor. Eine Option der Datenumwandlung ist die „Filterung“. Es ist möglich, nach einem bestimmten Lieferort oder einer bestimmten Gruppe von Lieferanten zu filtern und anhand der gefilterten Daten eine Prognose zu erstellen, um schnell an Informationen zu gelangen. Eine andere Taktik ist die „Aggregation“. Wenn uns tägliche Daten vorliegen, erhalten wir durch wöchentliche oder sogar monatliche Aggregation einen neuen Datensatz, der uns Aufschluss über bestehende saisonale Veränderungen und Trends gibt. Sobald die Daten auf diese Weise angereichert wurden, können wir sie visualisieren. Die Datenvisualisierung ermöglicht es, schnell einen Überblick über die Daten zu gewinnen. Sie hilft Data Scientists und den verschiedenen Anspruchsgruppen eines Unternehmens, sich auf Prozesse und die benötigte Datenqualität zu einigen. Das ist eine wichtige Feedback-Schleife in der CRISP-Methode, die dazu beiträgt, vorliegende Probleme besser zu verstehen. Aus der Perspektive der Datenverarbeitung hilft dies, schnell Muster und Ausreißer entdecken und entscheiden zu können, wie mit dem bestehenden Problem umzugehen ist. Python-Bibliotheken wie Matplotlib und Seaborn sind leistungsfähige Visualisierungstools, vor allem für technische Diskussionen und interne Iterationen zur Festlegung des Projektumfangs. Zudem kann Power BI (eine Business-Intelligence-Lösung von Microsoft) verwendet werden, um interaktive Dashboards für die Prototypentwicklung und als Machbarkeitsnachweis für Kunden zu erstellen. Um Qualität und Integration für Unternehmen zu gewährleisten, nutzen wir andere leistungsstarke Enterprise-Tools wie SAP Cloud Analytics. Häufig genutzte Plots für die EDA sind z. B.:
- Histogramme: zur Überprüfung der Verteilung einer bestimmten Variablen
- Scatter Plots: zur Überprüfung der Abhängigkeit zwischen zwei Variablen
- Karten: zur Darstellung der Verteilung einer Variablen auf einer regionalen Karte oder Weltkarte
- Korrelationsdarstellungen von Eigenschaften (Heatmap): zur Veranschaulichung der Abhängigkeiten zwischen verschiedenen Variablen
- Zeitreihendiagramme: zur Identifizierung von Trends und saisonalen Veränderungen in zeitabhängigen Daten
Ein Beispiel für ein Power-BI-Dashboard ist in Abbildung 2 dargestellt. 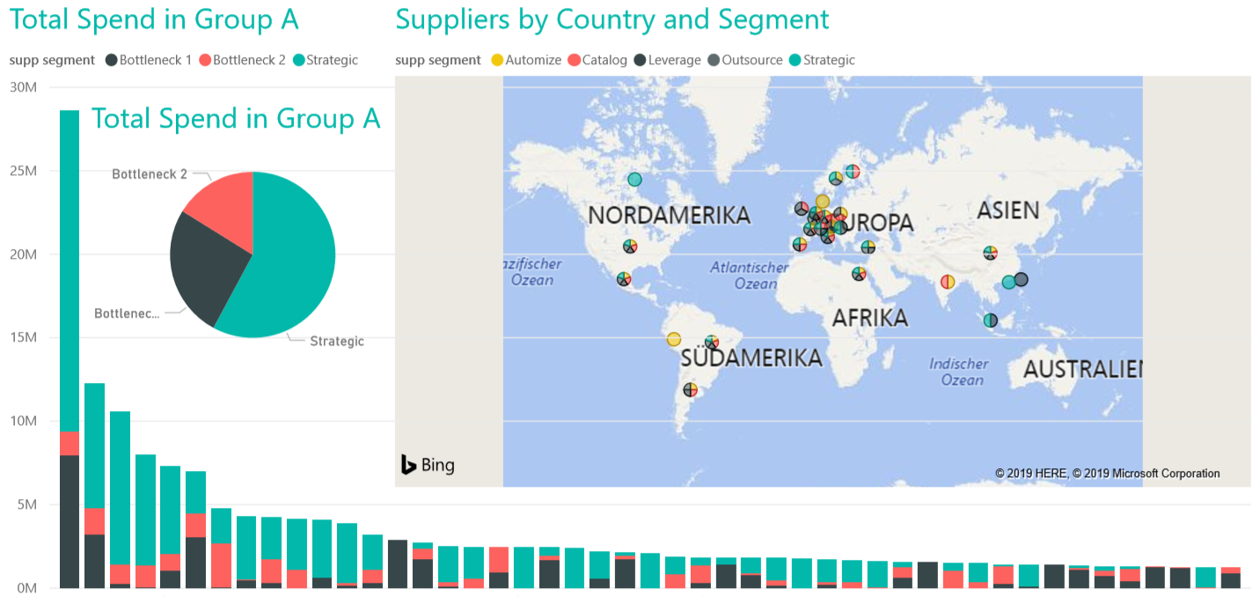 Abb. 2: Beispiel für ein Power-BI-Dashboard Nach Abschluss des EDA-Prozesses kann die Modellierungsphase beginnen. Diese umfasst die Erstellung statistischer Modelle und die Entwicklung von Machine-Learning-Modellen. Auch wenn die EDA bereits einige grundlegende statistische Analysen enthält, erfolgt die vollständige statistische Modellierung erst in der Modellierungsphase, die in Zukunft Gegenstand eines anderen Posts sein könnte.
Abb. 2: Beispiel für ein Power-BI-Dashboard Nach Abschluss des EDA-Prozesses kann die Modellierungsphase beginnen. Diese umfasst die Erstellung statistischer Modelle und die Entwicklung von Machine-Learning-Modellen. Auch wenn die EDA bereits einige grundlegende statistische Analysen enthält, erfolgt die vollständige statistische Modellierung erst in der Modellierungsphase, die in Zukunft Gegenstand eines anderen Posts sein könnte.
Fazit
Zusammenfassend kann man sagen, dass die explorative Datenanalyse ein entscheidender Schritt in jedem Data-Science-Projekt ist. Die Hauptsäulen der EDA sind Datenbereinigung, Datenvorbereitung, Datenexploration und Datenvisualisierung. Zur Durchführung der EDA stehen verschiedene explorative Tools (Python und R) und Enterprise-Anwendungen (Power BI, SAP Cloud Analytics, Tableau usw.) zur Verfügung, die jeweils eine einzigartige Zusammensetzung von Tools bieten.
Wir bedanken uns bei Dr. Ghazzal Jabbari und Frank Kienle für deren Beitrag zu diesem Artikel.
