
The automation of data management processes as well as system architecture requirements are some of the great challenges related to big data and the efficient handling of large data quantities. A Gartner Study from a few years ago estimated that automation could lead to a 45% reduction in manual data management tasks by 2022.
However, manual data maintenance processes and heterogenous system landscapes present companies with great challenges and are one of the key reasons why big analytical potential in the form of data exists, although it is not efficiently exploited. As a result, data-driven decision making is considerably difficult. CAMELOT has developed the Master Data Automation Framework in order to create an improved and data-driven decision-making basis.
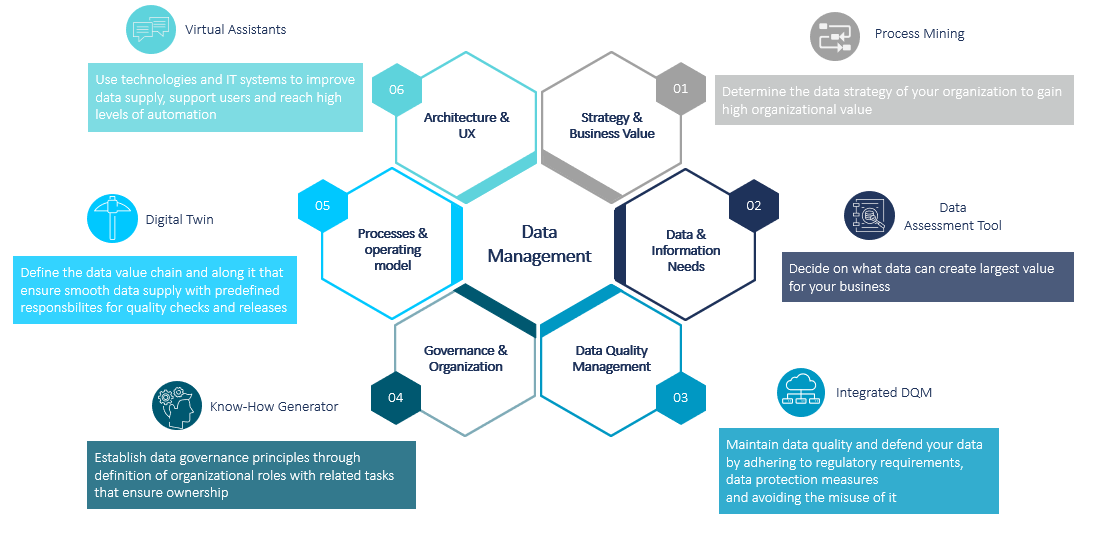
Scope for Automation Potential in the Data Management Strategy
The Master Data Management Automation Framework represents a schematic framework for the automation of your data landscape. In the first step, it is important that the selected data is that which will generate the greatest added value for your company. Further criteria are the information requirements that will fulfill your data as well as their data quality. This includes, in addition to data maintenance in the company, compliance with regulatory requirements, data security, and the prevention of unauthorized data access.
Data governance principles from these considerations should be established for paving the way to a data-driven company through, for example, the various roles and definition of their responsibilities. Processes must be defined to ensure that data availability is guaranteed where it is required. This causes a data value chain to be created with which the appropriate data supply to the necessary departments can be ensured. The technologies used for the required infrastructure, together with user support through intuitive user interfaces, play a particularly important role along this data value chain.
Most of the dimensions of the Master Data Management Automation Framework explained above are made possible through the use of technologies. Possible automation of these are listed below using examples.
- PROCESS MINING can help to identify and improve processes. Data mining and process analytics are used methodically here to generate added value for your company.
- The value of the available data can be determined using the Data Assessment Tool. The tool is very useful for supporting data specialists with table analysis, especially at the beginning of projects.
- Integrated Data Quality Management automates the continuous monitoring and maintenance of data quality in order to enable high-quality, data-driven decisions.
- The Know-How Generator serves to train and grow employees into their new data-responsible roles.
- With the help of DIGITAL TWIN TECHNOLOGY, a virtual mapping of an object or system throughout the entire life cycle can be completed. Data-driven decision making can be supported through real-time data and machine learning.
- Virtual Assistants can be put to a multitude of uses within the company during the data transformation. This is then often linked to 24/7 customer support. With Natural Language Processing and Machine Learning, the applications can be used in a bigger variety of settings.
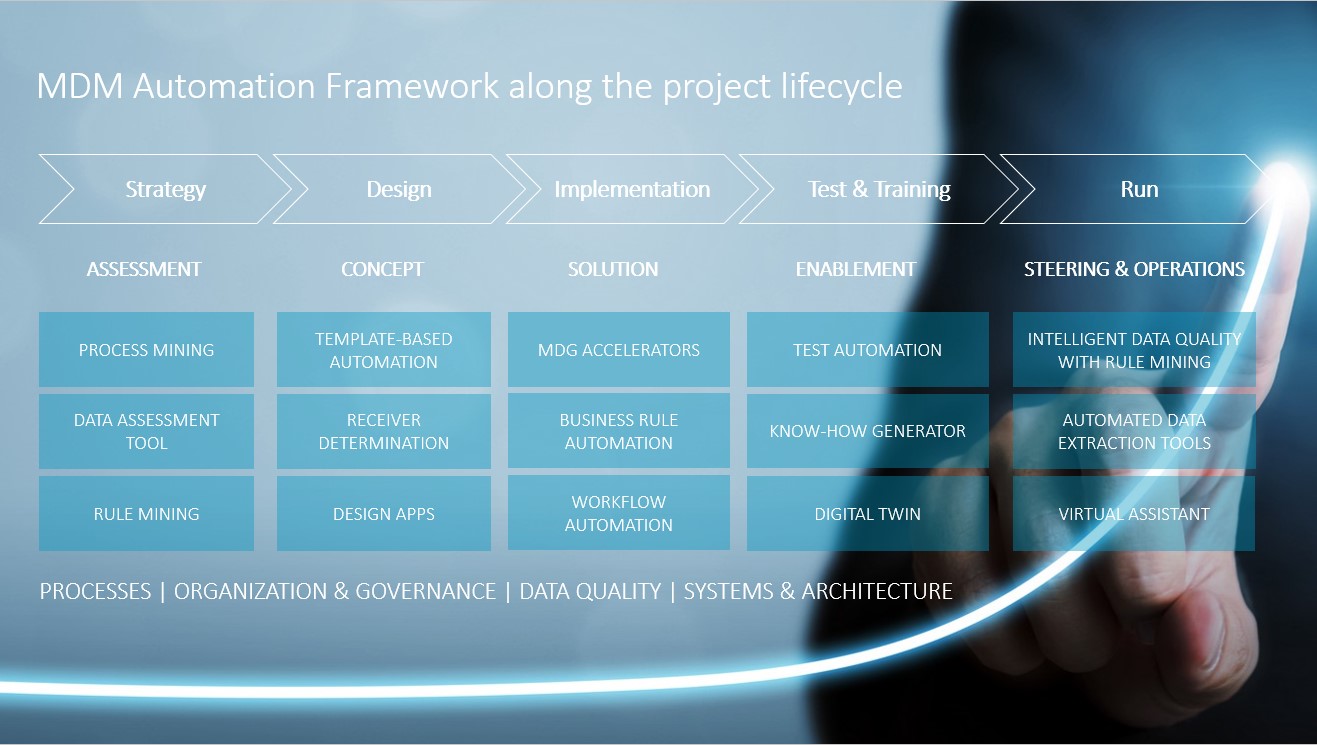
Phases During the Implementation of Automation Potential in Data Management
The implementation of automation in data management can be divided into project phases. At the beginning, there is a strategic phase that is designed, among other things, to evaluate and determine the status quo. This phase then segues into the design phase which serves as the conceptual first draft. Following this is the implementation of the solution in the implementation phase. At this stage, it is important to understand that the project phases are not over just because the implementation phase has been completed. After the “go live” comes the test & trainings phase, which ensures that the software development is free of bugs. Employees are continuously trained in functional aspects during this phase. In the last case which is dedicated to the operative use of the solution, use cases are deployed during actual operation and further automation potential becomes abundantly clear during this phase. Technologies including integrated data quality management combined with rule mining, data extraction tools as well as virtual assistants can be put to use here. Intelligent document processing should also be mentioned in this context as data capture in companies is often still done manually and is very resource intensive.
Design Thinking as Cornerstones of Successful Projects

In addition to these various conceptual frameworks for the implementation of automation in the course of data management, the methodical approach to finding solutions is also of essential. The Design Thinking approach, along with others, can serve this purpose well. The design thinking approach serves as a tool for firstly placing the methodical focus on understanding the problem and on the actual solution thereafter.
At CAMELOT several projects have already been concluded with the help of design thinking under the name “Data & Analytics Innovation Strategy Assessment”. A modular project lasting several weeks is in the background which can be held either in person or online. For example, the global data and analytics capabilities of the chemical industry were analyzed in various functional areas, and in the pharma industry application cases were developed by artificial intelligence and automation. The design thinking method can thus be applied across different industries.
In conclusion we can say that the Master Data Management Automation Framework offers a successful framework for implementing automation potential spanning various project phases using the design thinking approach.
We would like to thank Robert Rössler for his valuable contribution to this article.
