
Data Mesh is a new approach to data management based on domain-driven design. In many cases, it is a foundation to turn data into value as it overcomes the weaknesses that led to the shortcoming of current data warehouses and data lakes.
More and more data are generated in today’s enterprise data landscapes. At the same time, the wish to harness the value of data for basic and advanced analytics use cases increases. However, current data organizations and data architectures can hardly cope with the new requirements in the data analytics and data science area. Business complexity and sizes have pushed us towards a situation, where an organization’s agility and immunity to create value from data will decrease if we do not change the approach of data management.
Limitations of Established Data Platform Architectures
For decades, data platform architectures have been following monolithic patterns like data warehouses, complex data lakes or data lake houses. All of that is usually managed by a team of specialists taking care of the data landscape and its pipelines. This team of data specialists has to align with data owners, business specialists and requirement requesters to provide specific data sets. The members of this team have a very specific profile: while understanding the data and talking with the business specialists, they also need to be able to implement the data pipelines and structures in the specific system. Exactly this is the bottleneck in today’s data organization. Also, the centralization of data in the data warehousing layer often results in complex data structures which become increasingly difficult to maintain and govern the longer this layer exists.
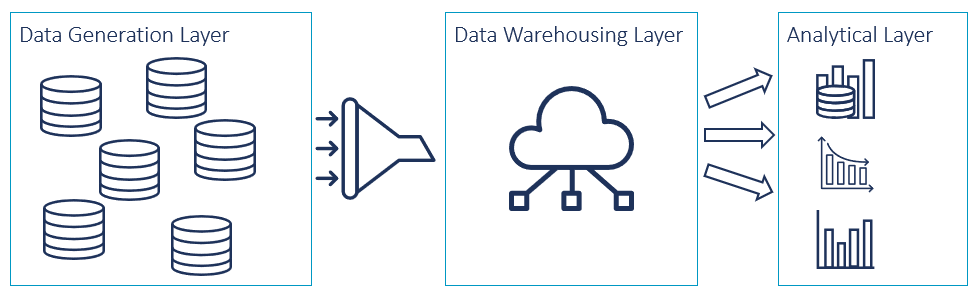 Figure 1: Layers of a traditional centralised data warehouse architecture
Figure 1: Layers of a traditional centralised data warehouse architecture
What Is the Data Mesh?
The concept of data mesh breaks with the existing patterns in order to prevent unmanaged, neglected and cluttered data lakes, so-called data swamps, from turning malicious (more in this article). Therefore, the monolithic centralized data architectures are re-organized following an approach based on domain-driven design. To achieve this, the ownership of the data is decentralized and assigned to domains whose teams are most intimately familiar with the data and are in control of it from the source. Other parties in the company can consume the ready-to-use data provided to them by the responsible domain as data products. It is the task of the domains’ cross-functional teams to define the data products from a business perspective, implement data pipelines and provide scalable endpoints which are accessible via modular interfaces. This way, we move the functionality of the long-established pipelines between the data-generating operational planes, centralized databases, and the analytical layer into the responsibility of the domains, making the process more efficient.
Domain architecture for a pharmaceutical company (example)
Figure 2 displays how a domain architecture could look like for a pharmaceutical company. For example, the commercial domain has so far been responsible for the operational “Sales Distribution” functionality in the ERP system and thus has already been familiar with the sales order data prior to the data mesh implementation. In the context of the data mesh, the domain’s responsibility is extended to provide its data to other consumers throughout the company as data products, e.g., the “Sales Order Data Product”. There will be one or several teams being responsible to define the data products and deliver them through defined analytical data endpoints (labelled “A” in fig. 2) at a defined service level and quality. On the other hand, for example the manufacturing domain might use the “Sales Forecast Data Product” to feed its “Material Planning” in the ERP system and generate a material forecast which will then be exposed as the “Material Forecast Data Product”.
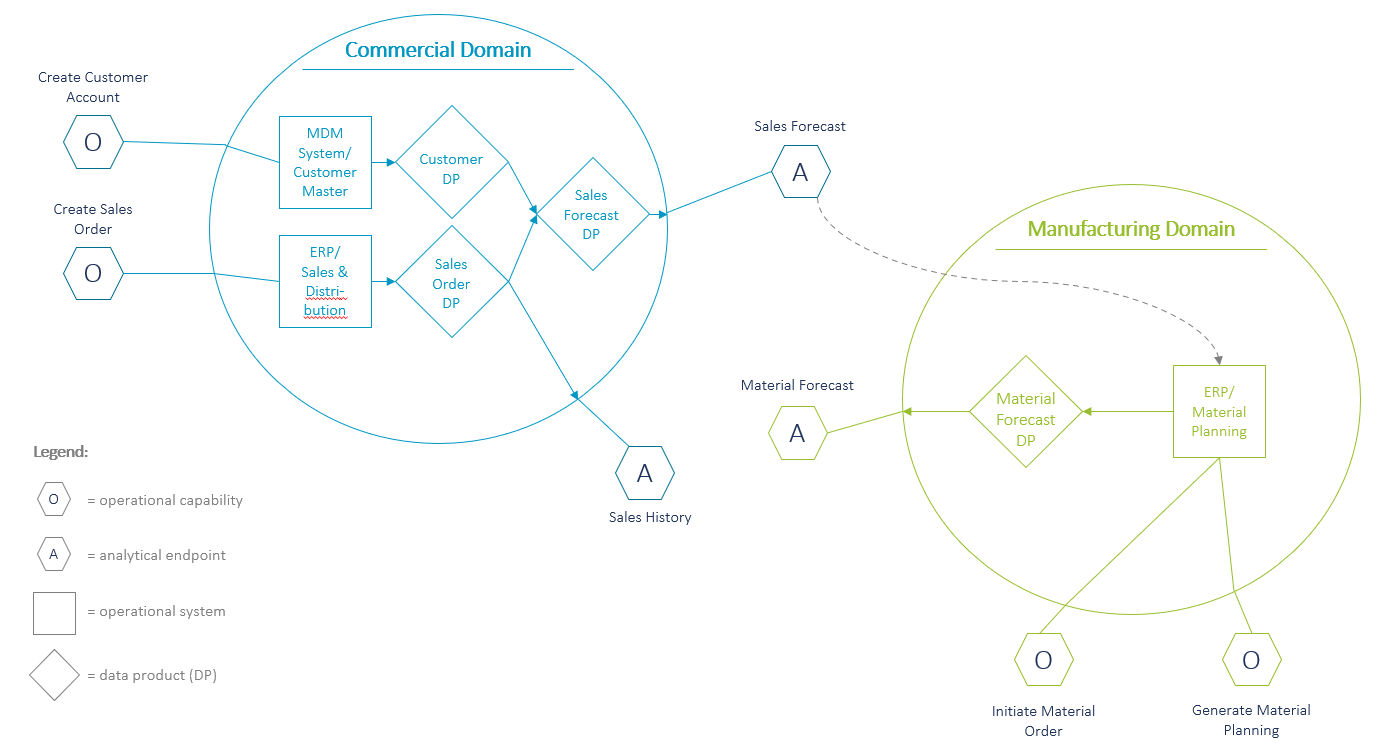 Figure 2: Example domain architecture for a pharmaceutical company
Figure 2: Example domain architecture for a pharmaceutical company
Data products break down the data architecture into independently deployable subsets which comprise the following aspects:
- Code which transforms, serves and shares the data product’s
- “Polyglot Data” and its metadata, meaning that data can exist in different formats (relational tables, graphs, events, etc.) depending on their source and type while maintaining the same semantic.
- Infrastructure that enables building, deploying and running the data product’s code, storage and access to big data and metadata.
Data-as-a-product can generate additional value and facilitate the usage of its users like data analysts and data scientists only if it is discoverable, addressable, trustworthy, self-describing, interoperable and secure. Therefore, we need a self-serve data platform that enables product owners to establish a high level of interoperability and interconnectivity between data products. At the same time, this centralized platform hides the complexity of the underlying infrastructure from the domain teams. This is essential as the technology stacks of big data and operational platforms have been diverging. Finally, it is crucial to establish a new federated approach on how to jointly agree on global rules and policies, in order to ensure that distributed data remain secure, governed and interoperable whilst attempting to preserve the domain’s autonomy in local decision-making.
Data Mesh: Data as a Product, Not an Asset Only
Summarized, data mesh interprets data as a product instead of an asset, making data more valuable and usable throughout the entire organization. In addition, it enables the following shifts among different corporate dimensions:
- Organizationally, it transitions from centralized ownership of the data to a decentralized data ownership structure. Thus, it enables direct peer-to-peer sharing of analytical data, allowing users to directly explore and use the data from the domain of its origin.
- Architecturally, data mesh circumvents the monolithic lakes and warehouses and connects data through a distributed mesh which is based on multiple independently deployable units connected through remote access protocols.
- Technologically, solutions will commence to treat data as one lively autonomous unit instead of seeing it as a by-product of running pipeline code.
- Operationally, data mesh alters data governance from a top-down centralized model to a federated model with global policies.
Does your Company Need Data Mesh?
When does it make sense to incorporate data mesh into your data landscape? As stated above, data mesh’s approach is to hold the candle to the continuously increasing quantity of data and complexity of organizations. This means that your company should be operating at scale where decentralization has the potential to improve your data architecture and does not merely introduce unnecessary complexity. This scale may emerge as a multi-heterogenous scattered system landscape, increasingly complex data structures, real-world data quantities (like sensor data), and a diverse set of data consumers. Furthermore, you might be facing significant operational cost for creating cross-process insights.
Additionally, if you are on the journey of joining process and data governance, data mesh supports your endeavor as it reduces complexity by breaking down the architecture into smaller pieces. The prioritization of data democratization and the pursuit of data governance as a core activity contribute to opening data siloes within your organization. Also, you might contemplate moving to a data mesh if your continuous intelligence cycle is measured in months or weeks instead of days or hours.
Knowledge and Skillset to Implement Data Mesh
Data mesh tackles the pain points and the underlying characteristics that led to the failures of the previous generations of data warehouses and data lakes. Therefore, we suggest switching to a completely new architectural pattern. The approach of data mesh is fairly new. Its implementation into any existing data landscape (or greenfield rollouts) requires a profound understanding and a diverse toolbox. These technologies and their right combination for each individual company call for professional knowledge and expertise in order to turn data to value.