
In December 2021, forecasting experts from all over the world met at the M5 conference to discuss the results of the latest “M-Competition”, the world’s biggest contest to challenge state-of-the-art forecasting. The results impressively demonstrate the power of forecasting methods that make use of machine learning (ML) algorithms and leverage multiple value-proven concepts to significantly increase forecast accuracy. This blog article introduces these concepts to help practitioners improve their demand forecasts and boost their demand planning process.
What Are Forecasting Competitions?
Demand forecasts are the basis for supply chain planning. For achieving outstanding planning, highly accurate demand forecasts are necessary. The importance of this topic is reflected in a large research community, which constantly works to find new concepts that help to increase forecast accuracy further. A major issue for all newly developed methods is their limited ability for generalization: The algorithms perform well on certain (artificial) data but fail to prove general value. To handle this issue, forecasting competitions were introduced. Here, the M-Competitions (named after their publisher: Spyros Makridakis) are the most popular. The latest one, M5, took place in 2020.
Forecasting Competitions: Why They Are Relevant for Practitioners
In these competitions, new forecasting methods are tested in terms of accuracy against each other as well as against established ones. The tests are based on extensive, real-world business data to ensure generalization and applicability for practice. For the M5-Competition, the aim was to forecast Walmart’s sales data on various aggregation levels, reflecting the publisher’s goal to make the competitions relevant for academia and practice.
In academia, forecasting competitions are known as important sources of innovation: In the M5-Competition, over 5,000 teams from all over the world participated and the results have been and are still widely discussed in papers and conferences. However, they get only limited attention within the industry: Have you heard about them? If not, we are happy to share the main findings and make them accessible to demand planners in the industry.
Main Findings from the M5-Competition
From a practical perspective, there are five main findings that can be derived from the M5-Competition. Most of them are related to new algorithmic concepts for increasing forecast accuracy. While all of those have proven value, the complexity and effort of implementation differs. Yet, for each level of sophistication in the demand planning process, some of the concepts are easily adaptable.
1. ML methods outperform simple forecasting algorithms
All winning algorithms of the M5-Competition leveraged machine learning (ML) methods. The idea of these is to create powerful algorithms which can learn from historical data. ML methods are highly effective in finding patterns and using this information to calculate very precise forecasts.
The superior performance of these methods was a bit surprising because before that, complex forecasting models had not been able to significantly outperform simpler ones (i.e., exponential smoothing models) for decades. This is the reason why those simpler methods have been and still are very popular in practice, even though they were developed back in the 1950s. However, ML methods have come a long way in recent years and are now more precise than simpler methods. Especially a combination of simple methods and ML capabilities have proven to be superior in providing the highest forecasting accuracy. This is nothing less than a paradigm shift in demand forecasting.
2. The value of learning across the whole portfolio
The most precise ML methods make use of additional information. One type of additional information lies within the own product portfolio and can be extracted with so-called cross-learning. The basic idea is to allow the forecasting method to learn from historical sales data of multiple related products or product groups. There are different ways to leverage this type of information, which all refer to cross-learning:
Cross-learning by aggregation describes the creation of multiple forecasts on different aggregation levels, which are combined for the final forecast. Hereby, patterns which are only observable on higher aggregates can be cascaded to lower product levels (see figure 1).
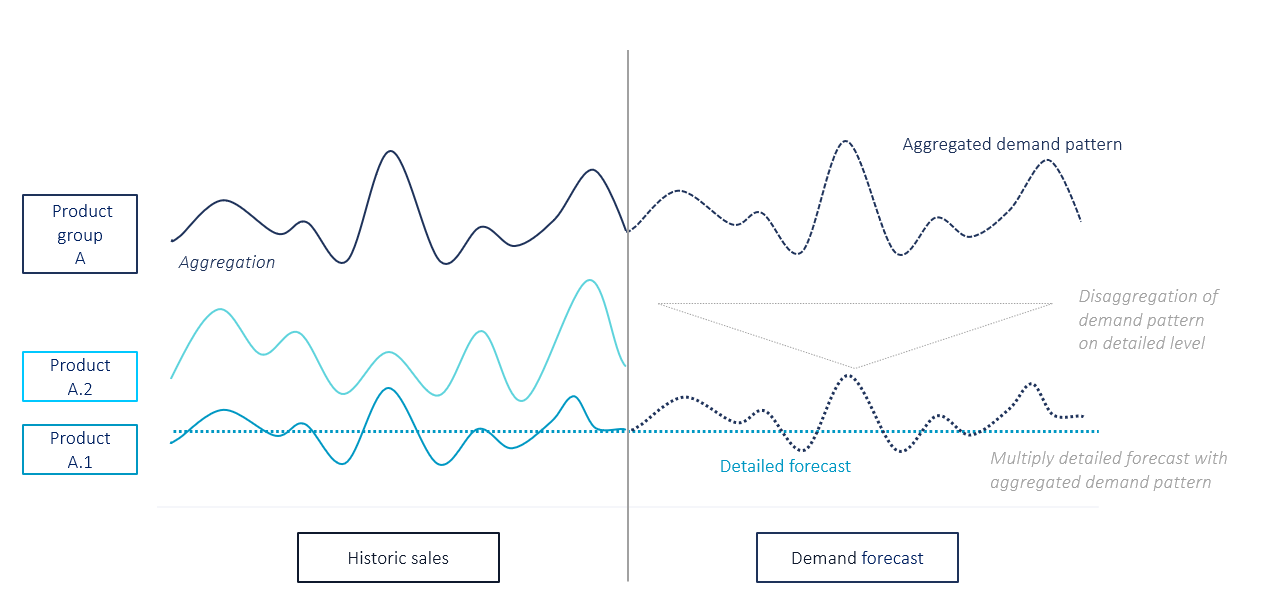 Figure 1: Cross-learning by aggregation
Figure 1: Cross-learning by aggregation
Cross-learning by dependencies is the incorporation of related time series as external inputs to explain the patterns of a single time series. This enables the model to leverage product interdependencies such as promotional effects (see figure 2).
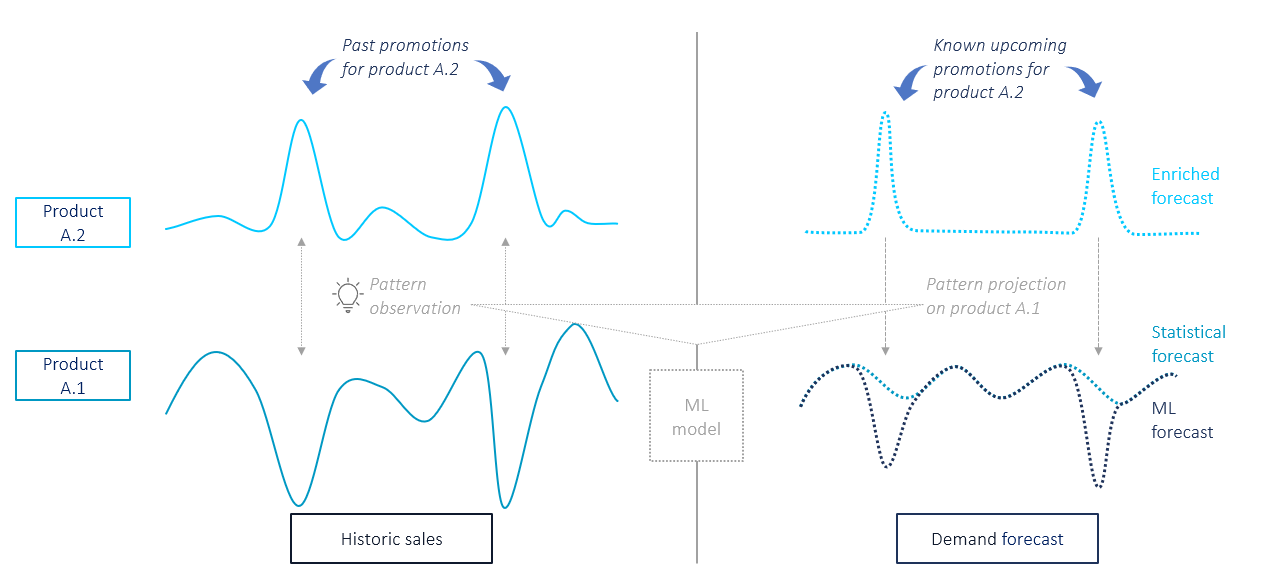 Figure 2: Cross-learning by dependencies
Figure 2: Cross-learning by dependencies
Global cross-learning is the establishment of one single powerful forecasting model for all products. Hereby, all available information is used, and the model can learn from different demand patterns within the whole dataset (see figure 3).
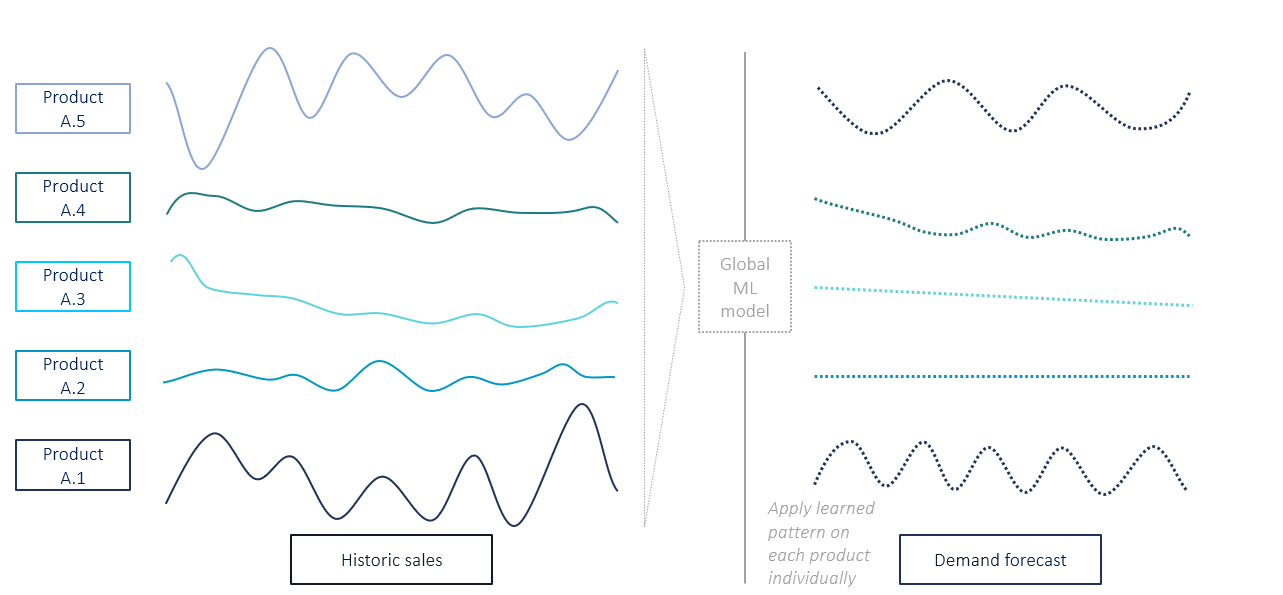 Figure 3: Global cross-learning
Figure 3: Global cross-learning
Cross-learning can highly increase forecast accuracy if the right data can be provided: hierarchical structured demand data with interdependencies between the products.
3. The value of using external data
Another relevant source in forecasting are all kinds of external data, which can explain parts of the variance in the demand history. These so-called explanatory variables can be industry indicators, raw material prices, internal promotions, etc.
For reasonable use of these data in demand forecasting, it is necessary that the variables have a causal impact on the demand and are not just correlated by chance. At the same time, they need to be available for future planning periods. If both conditions are fulfilled, they can be leveraged within many ML methods. While those are able to select only the most relevant explanatory variables, research suggests pre-selecting the variables provided to the algorithm. With that, the algorithm can leverage the most relevant variables out of a certain, pre-defined set for each product.
There is no general rule which explanatory variables should be used. Instead, the decision is business-dependent and requires some set-up effort. However, afterwards the process can be highly automated, and the value of those variables is uncontroversial.
4. Forecast method combination outperforms best-fit approaches
In addition to leveraging further information within forecasting, accuracy can also be increased by changing the way the decision is made about which methods to use.
For years, it has been best practice to use a best-fit approach for this purpose, whereby different forecasting methods are simulated on historic sales and the one which fits best is used for future forecasts. However, this practice has several disadvantages. The results of the M5-Competition show (and prove the findings of the previous M-Competition) that combining multiple forecasting methods solves the problems of using just one method. This is highly relevant because there are easy ways to implement forecast model combination approaches. For more information, see our next blog article focusing on this topic.
5. The need for probabilistic forecasting
When summing up the findings of the M5-Competition one topic needs to be mentioned, even if it might not directly be implemented in practice: The M5 was the first competition to question the approach of solely focusing on point forecasts (i.e., forecasting only one number per period). In addition to classical accuracy measures, all methods were also assessed based on their performance with regards to uncertainty of their forecasted values. This reflects the increased interest in probabilistic forecasting, whereby a distribution of forecasts is calculated for each period rather than a single value that is most likely. Yet, currently there is limited value of these techniques in practice as no advanced planning system is capable of using range forecasts for subsequent planning processes.
What Does That Mean for Practitioners?
You are now aware of the latest trends in demand forecasting. To put the lessons learned into practice, as a first step, determine the maturity level of your company’s demand planning process. Depending on the level of sophistication, the introduced concepts can either be directly adopted or are rather a long-term vision to achieve forecasting excellence. The application of simple ML algorithms (1), simple cross learning (2), incorporating external data sources (3), and combining multiple forecast methods (4) is realizable within standard planning systems. However, for the more sophisticated concepts and to directly use the winning models of the M5-Competition, you should use additional data science capabilities. For more detailed insights into this topic, make sure to read our following blog post on trends in demand forecasting.
Find out more in our next blog article The Fastest Way to Boost Forecasting Accuracy.
