
In this case Triple A stands for Analytics, Acceptance, Architecture.
Before applying this formula in the context of inventory optimization, it is first necessary to derive the relationship to decision support in general and the three A-components in particular.
When it comes to advanced and predictive analytics, software manufacturers and data evangelists often only look in one direction: towards the future. Instead, we start by looking in the rear-view mirror. In the 1990s, there were two large groups of successful companies in the industry, which, in simple terms, could be divided into “intuitive individualists” and “systematic strategists”. The first group was exemplified by a controlling and dominating entrepreneurial personality on the ground. The second group operated more on a technologized management basis, which would no doubt be referred to as data-driven today.
In retrospect, the question now arises as to who was more successful and which parameter should be used as evidence. Instead of getting lost in quality criteria for suitable indicators, we will keep things simple here: Anyone who makes more good decisions than bad ones may be considered successful. According to one study, the quality of corporate decision-making is aided above all by a good decision-making process. As a result, the profitability of the company can be increased by more than 30%.
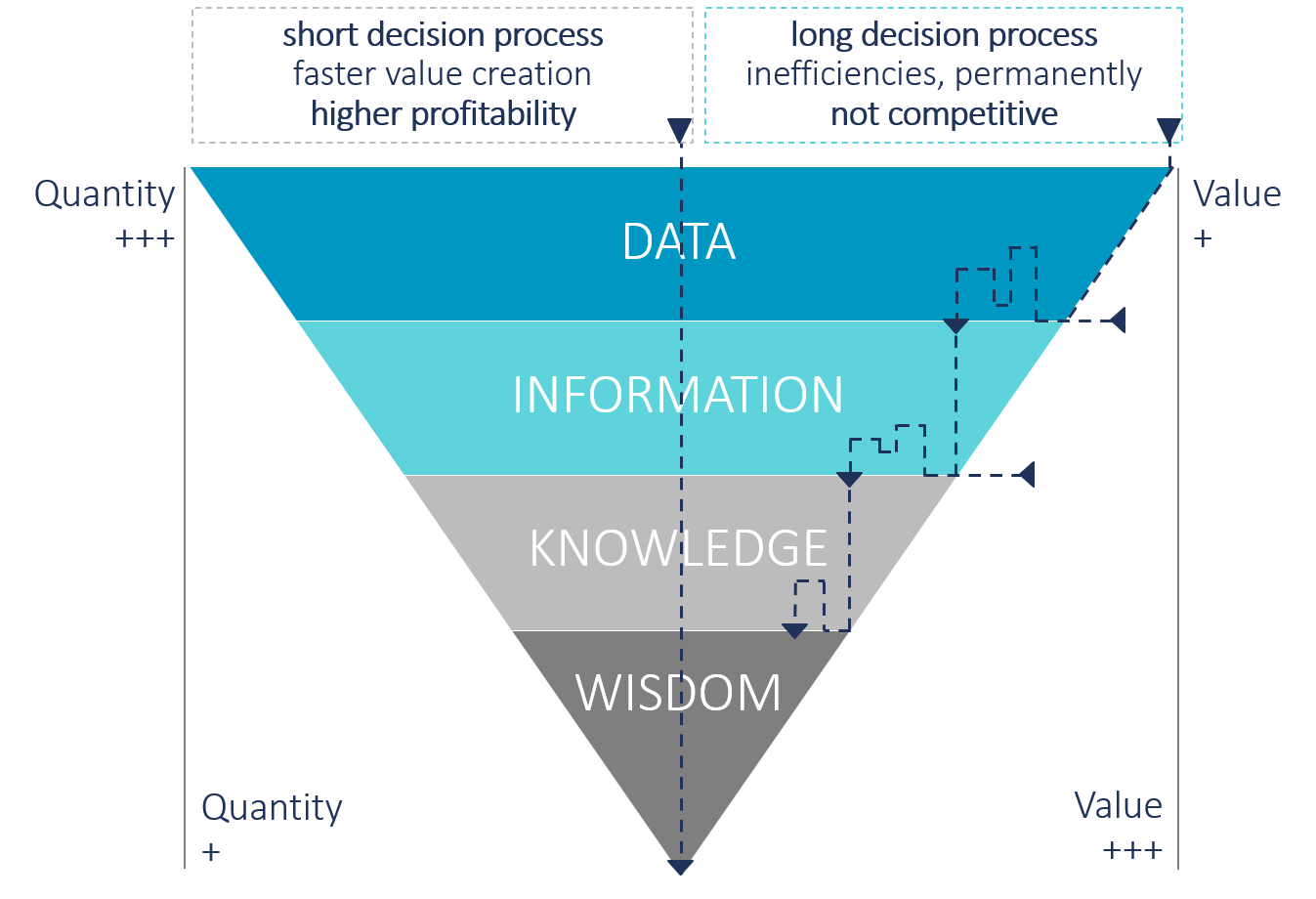
Figure 1: DIKW pyramid in decisions
Since the “systematic strategists” had already started to create the data basis and an effective decision-making process early (or at least earlier), they consequently benefit more than others. They have appropriate data warehouses. Analytics supports the identification of cause-effect relationships and facilitates well-founded decisions. It is precisely these data-driven decision-making processes that we would like to explore in this paper. People are not exactly predestined to make complex decisions, as theory demands of them.
This implies that a manager would have to know all alternative courses of action that lead to the goal, as well as all developments that might occur in future. He would have to have a precisely defined, complete and consistent idea of the criteria (so-called preferences) according to which he should evaluate all future scenarios that might occur as a result of his decisions. In addition, managers do not make decisions according to their personal preferences, but according to those of their clients, i.e. ultimately the owners of the company. Obviously, the theoretical requirements have little in common with the reality of decision-making. No one can have the necessary, all-encompassing level of information. Furthermore, one would have to constantly factor in the actual developments using complex calculations.
One might assume that machines would be able to improve this supposed weakness of human decision-making using analytical methods by applying artificial intelligence (AI) and thus overcoming cognitive limitations as well as biases.
This confidence in the decision-making competence of machines is misplaced. The quality of a developed algorithm depends largely on a precise and comprehensive understanding of the interdependencies of as many influencing factors as possible. For this reason, in the context of analytics, specialist departments, process experts and business consultants are just as crucial as data scientists. Structured in a way that is as interdisciplinary as possible, they contribute an abundance of perspectives, individual experiences or even preferences of the available alternative courses of action right at the beginning. This is where the potential of human intuition and the recognition of causal changes comes into its own. An optimal set-up would therefore involve interaction between humans and algorithms that complement each other through their respective strengths.
Based on our experience with the design and the implementation of business logics and planning functions in the context of data warehouses, we know how to establish them to achieve a high level of acceptance in specialist departments and with IT and BICC. The same quality criteria also provide good orientation for data science algorithms. If the procedures are quality-assured through governance and are embedded in a robust and at the same time flexible (bi-modal) architecture, this creates a solid foundation for use cases and data science initiatives and analytics projects. The figure illustrates the connection and at the same time the sensible coexistence of established (mostly on-premise) enterprise architecture and new (often cloud-supported) data science architecture.

Figure 2: Core and periphery
Let’s now test the previously mentioned aspects on the use case: Analytics for Inventory Optimization
The subject of inventory optimization is more relevant than ever. Balancing the typical conflicting goals of “reducing capital commitment” and “avoiding short sales through gaps in the product range” was already challenging in the past. Due to the delivery processes along the supply chain, this is now even more complex.
Although the initial response during the coronavirus pandemic was to align supplier networks more nationally, demand peaks and supply bottlenecks of primary products on the one hand or demand slumps on the other hand are a problem that threatens the existence of the company. Data-supported risk management is necessary here.
Analytics makes a decisive contribution not only to making the various delivery points visible, but ideally to forecasting them in real time and informing all network participants accordingly or advising them of changes. Today, analytics means not only the obvious integration of internal, mostly structured data, but also increasingly incorporating unstructured data into the algorithms to control the logistical flow of goods. Machine learning (ML) helps to evaluate and respond to obstacles in production and supply. Digitalization initiatives along the value chain from raw material to end customer now enable effective analytics use cases.
Companies typically do not start with digitalization and analytics initiatives on a greenfield basis, but move between the conflicting priorities of new technical requirements, investment protection, openness, and security. This can best be achieved with a hybrid approach that, on the one hand, considers the existing architecture and, on the other, offers the necessary flexibility and speed. The cloud plays an important role here, as it is the easiest way to network the supply systems of the network partners involved and to share information centrally and quickly. The requirements for supply chain resilience necessitate a corresponding technical environment.
In this form, decision support is efficient, transparent, and effective. Not only the network partners work together, but also man and machine. One approach to implementing such analytics solutions goes back to the concept of the digital twin, where the supply chain is digitally recreated using the data of the physical flow of goods. On this basis, analytics applications can predict possible supply bottlenecks or buffer stocks in advance and contribute to overall inventory optimization. In essence, networking with external partners, suppliers and customers provides the best (data) basis for responding quickly to changing trends and sudden crisis situations.
We recommend starting with manageable analytical use cases according to our process model. Initiatives that bring direct economic benefits and have failed in the past because of the computing power required, complexity in the statistical area or simply because of the data involved are promising. In “Data Design Sprints for Analytics”, we will be happy to demonstrate these possibilities with concrete use cases.
